MongoDB 应用架构之路
随着大数据时代的到来,传统的关系型数据库已经无法满足不同的存储需求,短短几年的时间NoSQL大行其道,大有后来居上之势。NoSQL根据不同的数据库类型又可以分为:文件存储、键值存储、列存储、图数据库、RTF存储等。本文我们一起来探索下基于文件存储最流行的NoSQL-MongoDB在实际架构中的应用。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库中功能最丰富、最像关系数据库的。他支持的数据库结构非常松散,是类似json的bjson格式,可以存储比较复杂的数据类型。Mongo完全遵循javascript语法,语法比较灵活,支持的查询功能非常强大,几乎可以实现关系数据单表查询的绝大部分功能,并且支持对表建立索引。
安装部署
下载
根据自己的操作系统从官网下载对应的MongoDB版本(32bit/64bit),32位的最大只能存放2G的数据,64位的则没有限制。下载后解压到安装目录。
启动
到bin目录下执行mongod --dbpath=..\db,其中dbpath参数为指定创建数据库文件的目录,该目录一定要存在,否则无法启动,如果嫌每次都输入参数太麻烦的话可以在bin目录下创建一个mongodb.config文件,将参数写到文件里面,下次启动的时候就可以直接执行mongod --config mongodb.config就可以了。
在浏览器中输入http://localhost:28017/可以查看mongodb的管理信息。
基本数据操作
在bin目录下执行mongo打开mongodb的客户端,默认连接的是test数据库。注意操作都是js的语法,可以根据自己的习惯来写。
insert操作
db.user.insert({name:’Jack’,age:30})
select操作
db.user.find({name:’Jack’})
update操作
db.user.update({name:’Jack’},{name:’Jack’,age:20})
remove操作
db.user.remove({name:’Jack’)}
这些都是最基本的操作,千万别以为就操作就这么简单,要知道js的语法是非常灵活的,要不然怎么实现关系型数据库的单表的大部分功能,但灵活的代价就是语句写起来比较复杂,高级的增删改查、索引、聚合、分类统计、MapReduce、游标等功能就不逐一介绍了,需要大家自己去多实践。
本文主要介绍MongoDB在应用架构中很重要的两个特性:主从复制、分片技术。
架构应用
既然是做应用数据库,我们肯定不希望把鸡蛋全放到一个篮子里面,单点部署是不应该被采用的,要知道如果碰到数据库宕机或者硬盘问题数据被永久破坏影响可想而知。幸好MongoDB可以做到读写分离、双机热备份和集群部署。下面来具体看下如何操作。
一、主从复制
1、模型图
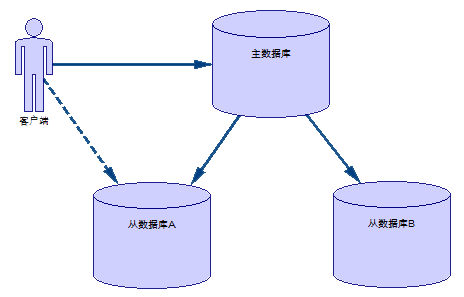
2、从上面的模型中我们可以分析出这种架构有如下好处:
1) 数据备份;
2) 数据恢复;
3) 读写分离;
3、实践
1) 我们把前面下载的安装文件再拷贝两份到其他的目录,模拟多服务器情况;
2) 启动一个作为主服务的mongodb,启动主服务器命令mongod --config mongodb.config --master,原来单启服务加了一个master参数,其他都没有变化,包括端口;
3) 启动另外一个mongodb服务作为从服务器,可以启多个,注意同一台机器需要换个端口,启动从服务器命令mongod --config mongodb.config --port=8888 --slave --source=127.0.0.1:27017;
4) 下面可以在两个数据库随便做点操作,我们可以看到数据在两个服务器上是同步更新的;
4、读写分离
这种手段在大一点的架构中都有实现,在mongodb中其实很简单,在默认的情况下,从属数据库不支持数据的读取,但是没关系,在驱动中给我们提供了一个叫做“slaveOkay”来让我们可以显示的读取从属数据库来减轻主数据库的性能压力,这里就不演示了。
二、副本集
1、这个也是很牛的主从集群,不过跟上面的主从集群还是有点区别:
1) 该集群没有特定的主数据库;
2) 如果主数据库宕机了,集群中会推选出一个从属数据库作为主数据库顶上,这就具备了自动故障恢复功能;
2、实践
下面的操作模拟三个mongodb的服务器,为了方便描述,这边起三个名字A(端口2222)、B(端口3333)、C(端口4444),其中设计A为集群主服务器、B为从服务器,C为仲裁服务器,所有操作都是在当前安装路径bin目录下执行的,开始操作如下:
1) 建立A服务器,mongod --config mongodb.config --port 2222 --replSet ailk/127.0.0.1:3333,replSet参数表示让服务器知道还有其他的数据库,指定端口3333的B服务器为下一个数据库;
2) 建立B服务器,mongod --config mongodb.config --port 3333 --replSet ailk/127.0.0.1:2222,解释同上;
3) 工作还没有完成,这个时候看下启动日志发现不停的在报replSet can't get local.system.replSet ...的错误,我们需要初始化一下“副本集”,随便连一个服务器,进入admin集合。
D:\Program Files\mongodb-win32-x86_64-2.4.5\bin>mongo 127.0.0.1:2222/admin
MongoDB shell version: 2.4.5
connecting to: 127.0.0.1:2222/admin
> db.runCommand({replSetInitiate:{
... _id:'ailk',
... members:[
... {
... _id:1,
... host:'127.0.0.1:2222'
... },
... {
... _id:2,
... host:'127.0.0.1:3333'
... }
... ]}})
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
这时候再看日志已经可以发现主从服务器都已经自动创建好了;
4) 创建仲裁服务器 C,mongod --config mongodb.config --port 4444 --replSet ailk/127.0.0.1:2222,在A admin集合中执行rs.addArb()追加即可。这里面需要说明下,仲裁服务器只参与投票选举。
> rs.addArb('127.0.0.1:4444')
{ "ok" : 1 }
5) 现在我们使用rs.status()来看下集群服务器的状态
ailk:PRIMARY> rs.status()
{
"set" : "ailk",
"date" : ISODate("2013-07-23T08:29:54Z"),
"myState" : 1,
"members" : [
{
"_id" : 1,
"name" : "127.0.0.1:2222",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1360,
"optime" : Timestamp(1374568146, 1),
"optimeDate" : ISODate("2013-07-23T08:29:06Z"),
"self" : true
},
{
"_id" : 2,
"name" : "127.0.0.1:3333",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 189,
"optime" : Timestamp(1374568146, 1),
"optimeDate" : ISODate("2013-07-23T08:29:06Z"),
"lastHeartbeat" : ISODate("2013-07-23T08:29:53Z"),
"lastHeartbeatRecv" : ISODate("2013-07-23T08:29:52Z"),
"pingMs" : 0,
"syncingTo" : "127.0.0.1:2222"
},
{
"_id" : 3,
"name" : "127.0.0.1:4444",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 48,
"lastHeartbeat" : ISODate("2013-07-23T08:29:54Z"),
"lastHeartbeatRecv" : ISODate("2013-07-23T08:29:53Z"),
"pingMs" : 0
}
],
"ok" : 1
}
看下stateStr节点就可以看出谁是主服务器、谁是从服务器、谁是仲裁服务器。
6) 最后来看下自动故障恢复功能,我们把主服务器 A 停掉,进入 B admin 集合执行 rs.status(),可以发现 B 服务器现在变成了主服务器了。
三、分片
有时候数据量比较大的时候我们需要把数据进行拆分,再把拆分后的数据分摊到每一个片上,这个地方有个“片键”的概念,也就是说拆分集合的依据是什么,按照什么键值进行拆分集合?
1、 模型图
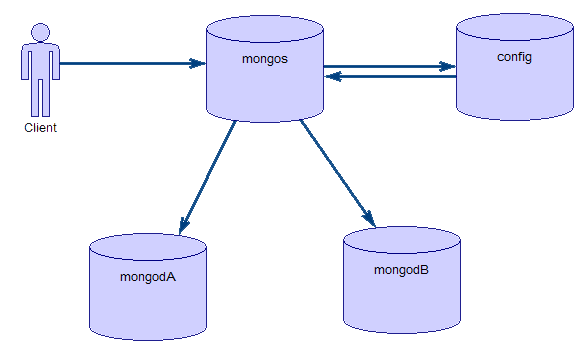
说明下:
mongos:就是一个路由服务器,它会根据管理员设置的“片键”将数据分摊到自己管理的mongod集群,数据和片的对应关系以及相应的配置信息保存在”config服务器”上;
mongod:就是一个普通的数据库实例。
2、 实践
根据上图可以看出来,这里需要用到4个mongodb的服务器,mogos服务器、config服务器、两个mogod单服务器;
1) 开启config服务器
mongod --config mongodb.config --port 2222
2) 开启mongos服务器
mongos --port 3333 --configdb=127.0.0.1:2222
3) 启动mogod服务器
mongod --config mongodb.config --port 4444
mongod --config mongodb.config --port 5555
4) mogos服务器配置
E:\mongodb-win32-x86_64-2.4.5\bin>mongo 127.0.0.1:3333/admin
MongoDB shell version: 2.4.5
connecting to: 127.0.0.1:3333/admin
mongos> db.runCommand({addshard : "localhost:4444", allowLocal : true})
{ "shardAdded" : "shard0000", "ok" : 1 }
mongos> db.runCommand({addshard : "localhost:5555", allowLocal : true})
{ "shardAdded" : "shard0001", "ok" : 1 }
这个时候已经为mongos服务器成功添加了两个mogod节点。
5) 开启数据库分片功能,指定集合中分片的片键
mongos> db.runCommand({enablesharding:'test'})
{ "ok" : 1 }
mongos> db.runCommand({shardcollection:'test.person',key:{name:1}})
{ "collectionsharded" : "test.person", "ok" : 1 }
6) 测试分片效果,插入10w条记录
mongos> use test
switched to db test
mongos> for(var i = 0; i < 100000; i++) {
... db.person.insert({name:'jacky'+i,age:i})
... }
mongos> db.printShardingStatus()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 3,
"minCompatibleVersion" : 3,
"currentVersion" : 4,
"clusterId" : ObjectId("51ee5bc0cdc1e6433d02a9a6")
}
shards:
{ "_id" : "shard0000", "host" : "localhost:4444" }
{ "_id" : "shard0001", "host" : "localhost:5555" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test", "partitioned" : true, "primary" : "shard0000" }
test.person
shard key: { "name" : 1 }
chunks:
shard0000 2
shard0001 1
{ "name" : { "$minKey" : 1 } } -->> { "name" : "jacky0" } on : shard0000 Timestamp(2, 1)
{ "name" : "jacky0" } -->> { "name" : "jacky9999" } on : shard0000 Timestamp(1, 3)
{ "name" : "jacky9999" } -->> { "name" : { "$maxKey" : 1 } } on : shard0001 Timestamp(2, 0)
可以看出shards已经是两个分片了,另外默认集合被分成了三段:无穷小->jacky0;jacky0-jacky9999;jacky9999-无穷大。但这个结果并不理想,因为他是按字母来排序的,也就是2库只分到了11条记录,绝大部分被分到了一库,不过分片的原理就是这样,具体的应用还是根据实际的需求来规划数据分键。
总结
大概也讲了不少了,NoSQL的强大也可见一斑,相比较以往关系型数据库而言NoSQL确实有很多优势,存储灵活、操作简单、性能高、易扩展等,但不是不要以为就可以完全替换关系型数据库,毕竟二者的应用场景不一样,没有最好的,只有最合适的。
另外MongoDB也是有自身的缺点的,下面大概说下他几个主要的缺点:
1) mongodb占用存储空间大。
这主要是由三个因素决定的。第一,mongodb的空间预分配方式,这样会让mongodb最多浪费不超过2G+2G文件大小的空间。第二,mongodb的字段名占用,即使是相同的字段,mongodb也会在每一个文档中都存储,这里会浪费极大的空间。第三,mongodb删除数据并不会释放空间,而只是将空间记录为删除状态以便重用。
2) mongodb没有事务模式
所以事务要求严格的系统慎用。
3) mongodb没有join
毕竟数据都是有关联的,虽然也能通过一定的方式变向的实现一些简单的连接功能,但对于业务复杂的场景也不适合。