一、介绍
1.1 概要
Flume 是 Cloudera 提供的日志收集系统,具有分布式、高可靠、高可用性等特点,对海量日志采集、聚合和传输,Flume 支持在日志系统中定制各类数据发送方,同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。
Flume 包括 0.9.x 和 1.x 两个版本,分别为 Flume-OG ( Flume Original Generation ) 和 Flume-NG ( Flume Next Generation ),Flume-OG 是一个分布式日志收集系统,有 Mater 概念,依赖于 zookeeper,其架构图如下所示:
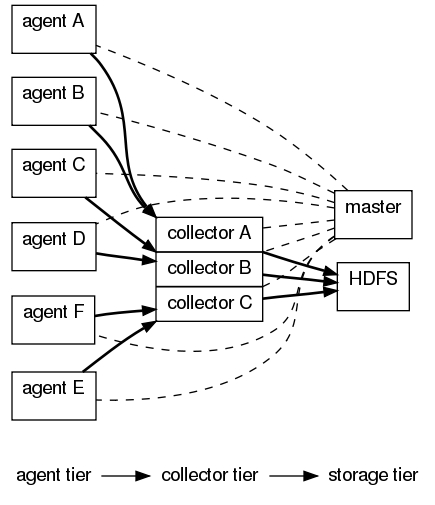
Agent 用于采集数据,agent 是 flume 中产生数据流的地方,同时,agent 会将产生的数据流传输到 collector。对应的,collector 用于对数据进行聚合,往往会产生一个更大的流。
而 Flume-NG,它摒弃了 Master和zookeeper,collector也没有了,web配置台也没有了,只剩下 source,sink和channel,此时一个agent的概念包括source,channel和sink,完全由一个分布式系统变成了传输工具。不同机器之间的数据传输不再是OG那样由agent到collector,而是由一个agent端的sink流向另一个agent的source,其架构图如下所示:
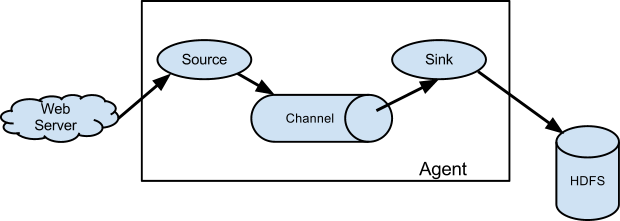
agent的source端,直接抓取数据或接收从前一个 agent 传送过来的数据,并将其转发到一个或多个 channel 进行缓存;
agent的 sink 端,从 channel 获取一个Event ( Flume-NG 的最小传输单元 ),然后传送到序列化端、下一个或多个agent 的source端。
Event 就像上图中箭头所示方向流动, chennel 的功能就像一个队列,暂时保存所有的 Event,为了保证传输一定成功,在 Event 送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
- 官方网站:http://flume.apache.org/
- 用户文档:http://flume.apache.org/FlumeUserGuide.html
- 开发文档:http://flume.apache.org/FlumeDeveloperGuide.html
1.2 系统要求
- Flume 使用 java 编写,其需要运行在 Java1.6 或更高版本之上;( 推荐 Java1.7 )
- 保证有足够的内存空间让 Flume 的 source、 channel和 sink 使用;
- Flume 的 channel 和 sinks 组件会有文件缓存到物理硬盘中,需要足够的硬盘空间;
- Flume 会读取文件或目录,需要 agent 相关的文件目录的 读写 权限。
二、基本组件
2.1 Agent 之 Source
source 可以接收外部源发送过来的数据,不同的 source,可以接受不同的数据格式,如:
- 目录池数据源(Spooling Directory Source),可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容;
- 命令行数据源(Exec Source),可以运行指定的shell命令(如:
tail -f [ file ])等,将产生的标准输出(或标准错误输出,需要配置)封装到 Event 中,向指定的 channel 发送; - 自定义源(Custom Source),用户自定义的源,会重点介绍。
2.2 Agent 之 Channel
channel 是一个存储地,接收 source 的输出,直到有 sink 消费掉 channel 中的数据。channel 中的数据直到进入到下一个channel中或者进入终端才会被删除。当 sink 写入失败后,可以自动重启,不会造成数据丢失,因此很可靠,常用的有:
- Memory Channel,将从 source 得到的 Event 都缓存到内存当中,存取速度快、高效,但是一旦 agent 崩了,缓存的数据无法恢复,可靠性不是太好;
- File Channel,跟Memory Channel相对的,此处将得到的 Event 都缓存到本地磁盘的文件当中,存取访问速度没有内存高效,但是可靠性强,一旦 agent 进程死掉重启后,所有缓存的 Event 可以全部恢复;
- Spillable Memory Channel, 前面两者的结合使用,首先发过来的 Event 都缓存到内存当中,一旦内存空间不够用了,就缓存到本地文件中,主要应用于内存空间不足,而硬盘空间充足的情况。
2.3 Agent 之 Sink
sink 会消费 channel 中的数据,然后送给外部源或者其他 source。如:
- HDFS Sink/HBase Sink,根据配置将 Event 所包含的信息保存到本地 HDFS/HBase 中;
- Logger Sink,顾名思义,将接收到的信息日志输出,主要用于测试和调试;
- Avro Sink,说句实话,百度得知 Avro 是一个 Apache 的数据序列化的系统,具体是什么不需要关注,只需要知道 Avro Sink 是将接收到的数据转换为 Avro, 然后发送到下一个 Agent 的 Avro Source,多用于Agent 与 Agent之间的数据连接;
- 用户自定义(Custom Sink),重点介绍。
三、安装与运行
到官方网站下载,http://flume.apache.org/download.html,下载完成解压完成即可使用:
cd ~/tools
wget -c http://mirrors.hust.edu.cn/apache/flume/1.5.2/apache-flume-1.5.2-bin.tar.gz
# 等待下载完成
tar -xvf apache-flume-1.5.2-bin.tar.gz
ln -s apache-flume-1.5.2-bin flume-ng ( 将 ~/tools/flume-ng加入到环境变量FLUME_HOME中 ) ====> 个人习惯,可不做
cd flume-ng
bin/flume-ng help # 查看flume-ng命令
或通过编译源码的方式安装:
cd ~/tools
wget - http://mirrors.hust.edu.cn/apache/flume/1.5.2/apache-flume-1.5.2-src.tar.gz
tar -xf apache-flume-1.5.2-src.tar.gz
cd apache-flume-1.5.2-src
# 跳过测试
mvn clean install -DskipTests
3.0 配置文件说明
Flume 的 Agent的各个部件都是通过配置文件来实现的,Agent、Sources、Channels和Sinks的定义,如下:
a1.sources = r1 r2
a1.sinks = k1 k2
a1.channels = c1 c2 其中`a1`是定义的 Agent 的名字,也是启动命令时`--name <agent>`中的`<agent>`为 `a1`;上代码Sources、Channels和 Sinks分别定义了两个分别为r1, r2, c1, c2, k1, k2;
定义每个Sources的类型,如:
a1.sources.r1.type = avro
a1.sources.r1.bind = localhost
a1.sources.r1.port = 33333
a1.sources.r2.type = netcat
a1.sources.r2.bind = localhost
a1.sources.r2.port = 44444 其中 `Source r1`定义为 Avro Source,监听 `http://localhost:33333`,`Source r2`定义为 NetCat Source;定义Channels 和 Sinks的方式跟 Sources类似;
为Sources 和 Sinks 绑定 Channels,如:
# 为sink绑定时,为channels
a1.sources.r1.channels = c1
a1.sources.r2.channels = c2
# 为sink绑定时,为channel
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2 注意:其中 Sources绑定 Channels时,为 `<agent>.sources.<source>`***`.channels`***;而 Sinks则为 `<agent>.sinks.<sink>`***`.channel`***。
3.1 启动 Agent
在 flume-ng/conf 目录下新建一个 mytest.conf做一个测试,内容如下:
# 定义了一个agent( a1 ), 一个source( r1 ), 一个channel( c1 ), 一个sink( k1 )
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 定义source( r1 )为Netcat Source,监控localhost:44444
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 定义sink( k1 )为Logger Sink,将接收的数据显示到命令行
a1.sinks.k1.type = logger
# 用内存作为 channel 的缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source 和 sink 绑定到 channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在 ~/tools/flume-ng 目录下执行如下命令启动 Agent :
bin/flume-ng agent -n a1 -c conf -f conf/mytest.conf -Dflume.root.logger=INFO,console
或
bin/flume-ng agent --name a1 --conf conf --conf-file conf/mytest.conf -Dflume.root.logger=INFO,console
参数说明:
-n指定 Agent 名称-c指定配置文件目录-f指定配置文件-Dflume.root.logger=INFO,console设置日志等级
注:
-Dflume.root.logger=INFO,console表示在控制台输出日志,用作测试或调试,真是生产缓存不用;- 使用logger,
flume-ng/conf目录下必须有log4j.properties项,否则会报错; - 在实际运行中,有时候就算 conf 目录下有
log4j.properties运行还是报错,如果你用的时第二条启动命令的话,换第一条启动命令试试;
在 Agent 成功启动后,新打开一个命令行,输入 telnet localhost 44444,
$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hello World!
OK 控制台输出:
2015-04-28 11:50:23,091 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:150)] Source starting
2015-04-28 11:50:23,150 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:164)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
2015-04-28 11:51:57,185 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 48 65 6C 6C 6F 20 57 6F 72 6C 64 21 0D Hello World!. } 如果显示如上所示,则 Flume-NG 安装成功。
3.2 第三方插件
plugins.d 目录
plugins.d 目录位于 $FLUME_HOME/plugins.d,在flume-ng 启动的时候,flume-ng 启动脚本会遍历 plugins.d 目录中的插件,当通过 java 启动的时候将它们嵌入到合适的路径,其目录结构:
plugins.d
|- lib 插件的jar包
|- libext 插件依赖的jar包
|- native 必须的本地库,如:*.so文件
如:
plugins.d/
plugins.d/custom-source-1/
plugins.d/custom-source-1/lib/my-source.jar
plugins.d/custom-source-1/libext/spring-core-2.5.6.jar
plugins.d/custom-source-2/
plugins.d/custom-source-2/lib/custom.jar
plugins.d/custom-source-2/native/gettext.so
四、数据获取
Flume 支持大量从外部源获取数据的机制。
4.1 RPC
一个Flume中部署的 Avro 客户端,能够通过 avro RPC 机制,将一个指定的文件发送给 Flume 的 Avro Source:
$ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10 上面所示命令将会把 `/usr/logs/log.10` 文件的内容发送到 Flume Source 监听的端口上。 ### 4.2 Executing commands
还有就是前面提及过的 Exec Source,通过执行一个指定的命令,将输出结果中的一行( 文本后跟回车\r或换行符\n,或两者同时出现 ),作为数据发送出去。
注意:Flume 不支持 tail 作为一个Source,但可以通过在 exec source 中使用 tail 命令将文件转换为数据流。
4.3 Network streams
Flume 支持下面的机制从常用的日志数据流类型中读取数据,例如:
- Avro
- Thrift
- Syslog
- Netcat
下面可以启动一个 avro-client 客户端生产数据:
bin/flume-ng avro-client -c conf -H localhost -p 41414 -F /etc/passwd -Dflume.root.logger=DEBUG,console
五、配置多 Agent 数据流动
通过 Agent 的Avro Source 和Avro Sink 可以实现多个 Agent 之间的数据传输,

agent foo 的配置如下:
# agent foo
foo.sources = r1
foo.channels = c1
foo.sinks = k1
foo.sources.r1.type = netcat
foo.sources.r1.bind = localhost
foo.sources.r1.port = 44444
foo.channels.c1.type = memory
foo.channels.c1.capacity = 1000
foo.channels.c1.transactionCapacity = 100
foo.sinks.k1.type = avro
foo.sinks.k1.hostname = localhost
foo.sinks.k1.port = 44445
foo.sources.r1.channels = c1
foo.sinks.k1.channel = c1
agent bar 的配置如下:
# agent bar
bar.sources = r1
bar.channels = c1
bar.sinks = k1
bar.sources.r1.type = avro
bar.sources.r1.bind = localhost
bar.sources.r1.port = 44445
bar.channels.c1.type = memory
bar.channels.c1.capacity = 1000
bar.channels.c1.transactionCapacity = 100
bar.sinks.k1.type = logger
bar.sources.r1.channels = c1
bar.sinks.k1.channel = c1 注意:Avro Source 中指定ip地址的是`<agent>.sources.<source>.bind = ip`,而 Avro Sink 则为`<agent>.sinks.<sink>.hostname = ip`!
5.2 合并 Agent
在日志收集当中,一个非常常见的情况是:大量的客户端将产生的日志数据发送到少量的收集 Agent 上,这些 Agent 再将接收到的日志存储到链接的存储系统上。如:
将数百台web servers 产生的日志发送到12个 Agent 上,然后写入到 HDFS 集群中。
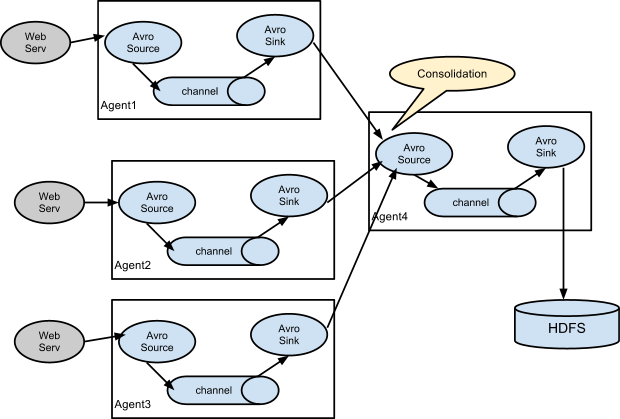
上图所示可以通过在 Flume 中配置3个使用 Avro Sink 的Agent,将3个节点都连接到一个 Avro Source的Agent( 同样的也可以使用 Thrift Sources/Sinks/Client来实现 )。图示 Agent4 收集接收到的 events,缓存到一个单一的 channel中,最后通过一个 sink将其中的数据发送到目的地( 如图所示的 HDFS )
5.3 多路 Agent
Flume 支持多路传输 event到一个或多个目的地。能够通过定义一个多选器( 能够通过路由,复制或选择的将一个Event发送到一个或多个 channels上 )来实现,其 Agent 结构如下所示:
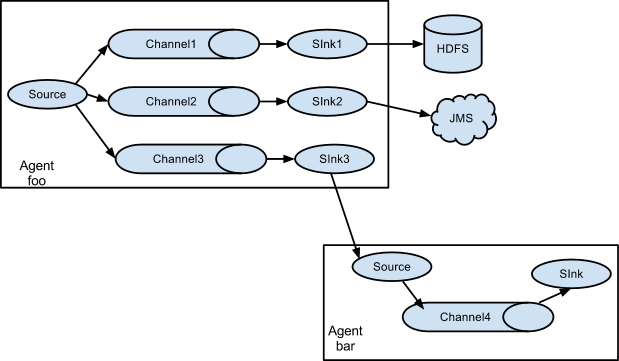
这种模式,有两种方式:
-
一种是用来复制(Replication),Replication方式可以将最前端的数据源复制多份,分别传递到多个channel中,每个channel接收到的数据都是相同的,配置格式如下:
# List the sources, sinks and channels for the agent replicatAgent.sources = r1 replicatAgent.sinks = k1 k2 k3 replicatAgent.channels = c1 c2 c3 replicatAgent.sources.r1.type = netcat replicatAgent.sources.r1.bind = localhost replicatAgent.sources.r1.port = 44444 replicatAgent.sources.r1.selector.type = replicating replicatAgent.sinks.k1.type = HDFS #... replicatAgent.sinks.k2.type = JMS #... replicatAgent.sinks.k3.type = avro #... # set channel for sinks replicatAgent.sinks.k1.channel = c1 replicatAgent.sinks.k2.channel = c2 replicatAgent.sinks.k3.channel = c3 # set list of channels for source (separated by space) replicatAgent.sources.r1.channels = c1 c2 c3 上面指定了 selector 的 type 的值为 replication,使用的Replication方式,`Source r1`会将数据分别存储到 `Channel c1 c2 c3`,这三个 channel 里面存储的数据是相同的,然后数据被传递到 `Sink k1 k2 k3`。 -
另一种是用来分流(Multiplexing),selector可以根据header的值来确定数据传递到哪一个channel,配置格式,如下所示:
multiplexAgent.sources = r1 multiplexAgent.sinks = k1 k2 k3 multiplexAgent.channels = c1 c2 c3 # Mapping for multiplexing selector multiplexAgent.sources.r1.selector.type = multiplexing multiplexAgent.sources.r1.selector.header = state multiplexAgent.sources.r1.selector.mapping.CZ = c1 multiplexAgent.sources.r1.selector.mapping.US = c1 c3 multiplexAgent.sources.r1.selector.mapping.TW = c3 #... multiplexAgent.sources.r1.selector.default = c2 #... 其余配置不再给出
5.4 load_balance
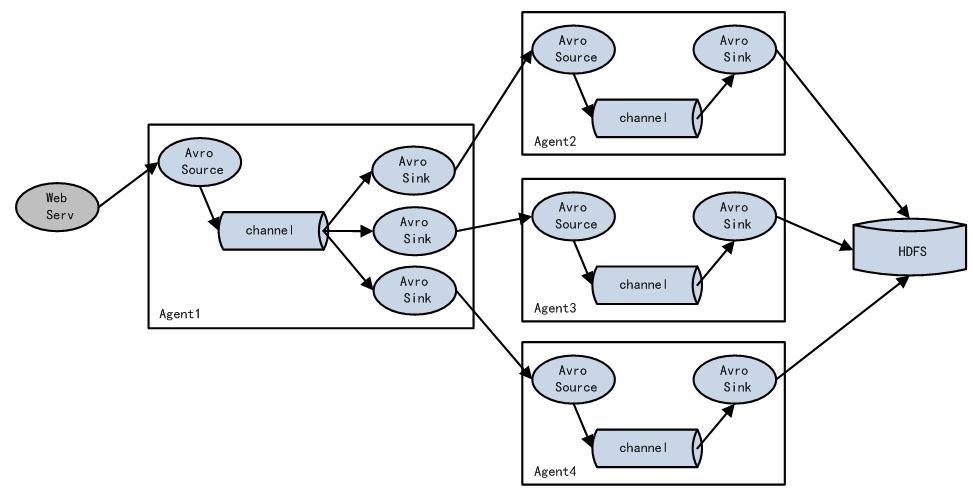
Load balancing Sink Processor能够实现load balance功能,上图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上,示例配置,如下所示:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
5.5 failover
Failover Sink Processor能够实现failover功能,具体流程类似load balance,但是内部处理机制与load balance完全不同:Failover Sink Processor维护一个优先级Sink组件列表,只要有一个Sink组件可用,Event就被传递到下一个组件。如果一个Sink能够成功处理Event,则会加入到一个Pool中,否则会被移出Pool并计算失败次数,设置一个惩罚因子,示例配置如下所示:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 7
a1.sinkgroups.g1.processor.priority.k3 = 6
a1.sinkgroups.g1.processor.maxpenalty = 20000
===
未完待续。。。