一、网络爬虫
网络爬虫或者叫网络机器人是用来自动采集网络内容的工具,通常被用于搜索引擎。基于我自己的理解,要写一个网络爬虫通常要解决以下几个问题:
- 有哪些网络资源是需要被爬取的。网络上的资源多种多样,有单纯的HTML页面,也有各种格式的文件、音频或视频等等,在本文中我仅爬取HTML页面中的文本,所以这里的首要问题是哪些URL是爬虫要处理的。
- 如何从文本中提取到我想要的信息。HTML文本中包含了很多无用的信息,包括标签等,网络爬虫最终提供给我的应该是我感兴趣的内容。
- 如何把爬取到的信息保存下来。爬虫得到的有用信息要通过数据库或其他有效途径保存下来。
- 其他问题:包括网站的反爬虫策略、爬虫策略、错误处理能力等等。
以上几个问题如果单独提出来可能大家都有解决的办法,但是整合到一起处理,还是有一些麻烦的。Scrapy这个爬虫框架就提供给我们一个简单的解决方案。
二、Scrapy
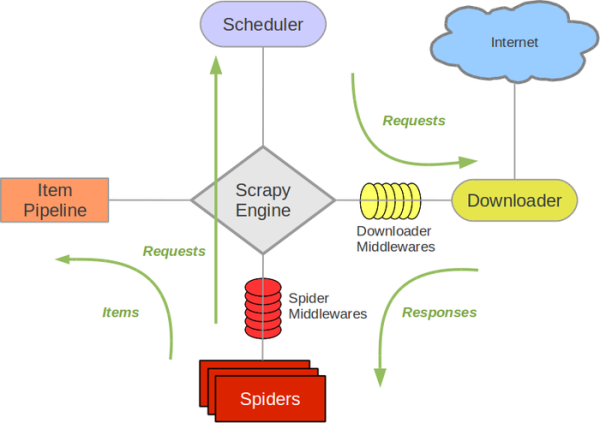
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。它包含了几大组件:
- Scrapy engine:它负责数据流在系统中所有组件中流动,相当于爬虫的“大脑”,是调度中心。
- Downloader:负责获取页面并提供给引擎。
- Spider:是真正的爬虫,负责URL和解析HTML提供item。
- Pipeline:负责处理spider提供的item。典型的应用有清理错误、持久化等。
- Middlewares:处理spider的输入和输出。典型的应用有网络代理验证。
三、新建一个项目
在写爬虫之前我们要新建一个项目,Scrapy非常贴心的为我们提供了一个命令帮助我们建立项目框架:
scrapy startproject [project_name]
这个命令建立的项目框架如下:
project_name/
scrapy.cfg
db/
__init__.py
config.py
spiders/
__init__.py
spider.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
- scrapy.cfg: 项目的配置文件。
- db/config.py:数据库的设置文件。
- spiders/:爬虫所在的目录。
- project_name/items.py: 项目中的item文件。
- project_name/pipelines.py: 项目中的pipelines文件。
- project_name/settings.py: 项目的设置文件。包括数据库设置等。
- project_name/spiders/: 放置spider代码的目录。
四、编写一个爬虫
房子这两年大热,这里我写一个爬取链家网二手房的爬虫为例。打开网页来观察一下结构:
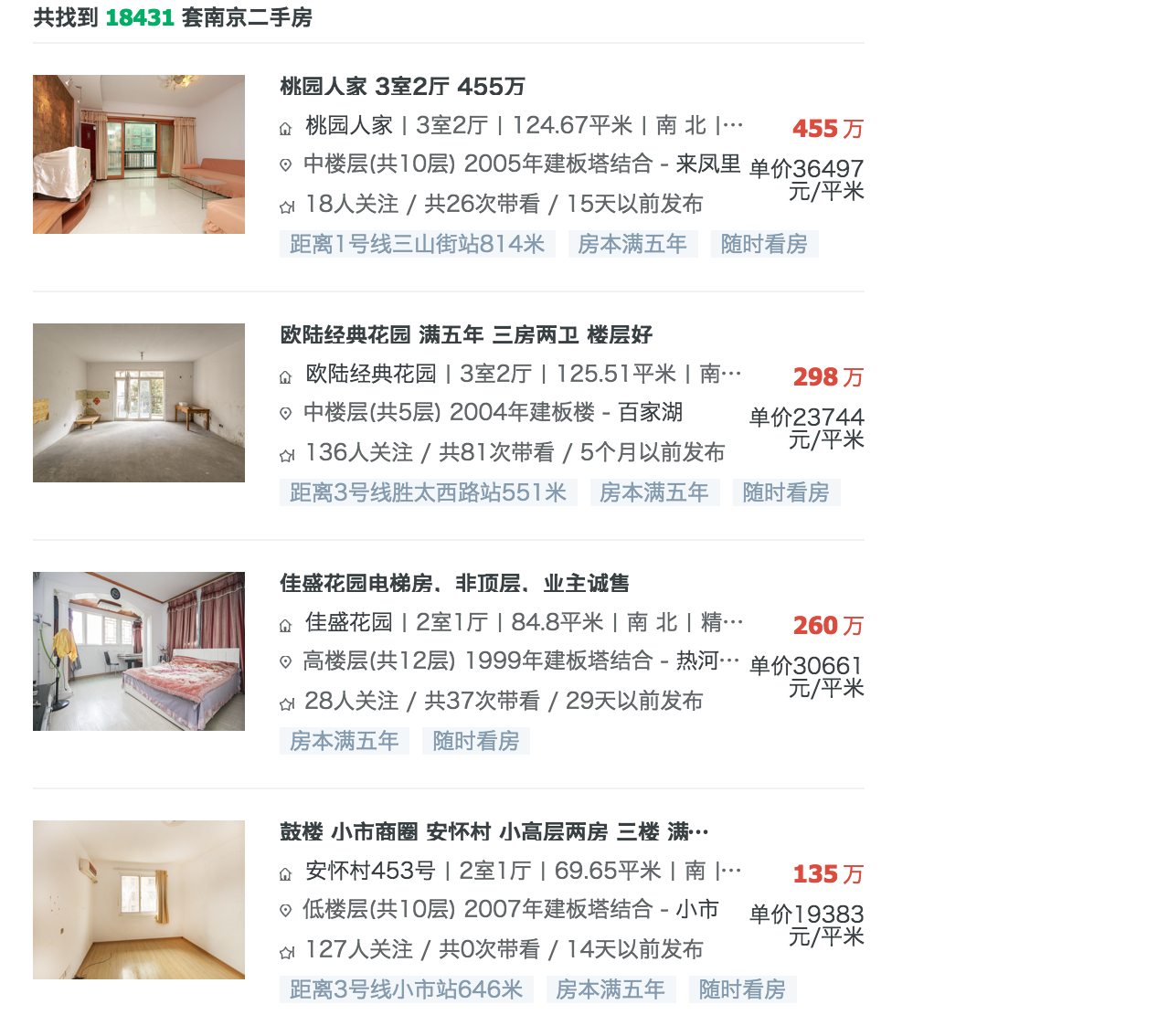
网页看上去十分规整,包含了很多我们想要的信息,包括总价、单价、面积和位置等。
声明item
Item是spider得到的结构化数据。
打开items.py,用Python简单的class定义语法来新建一个类:
import scrapy
from scrapy.loader.processors import MapCompose, TakeFirst
class HomeLinkItem(scrapy.Item):
hid = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
room = scrapy.Field()
htype = scrapy.Field()
area = scrapy.Field()
areaName = scrapy.Field()
爬虫
在spiders/目录下新建home_link.py,作为爬虫。
class HomeSpider(CrawlSpider):
name = "home_link"
def parse_item(self, response):
...
爬虫要知道从哪里爬取,所以第一步是告诉爬虫域名和开始的URL:
allow_domains = ['nj.lianjia.com']
start_urls = ['http://nj.lianjia.com/ershoufang/']
爬虫开始抓取网页之后还有告诉爬虫哪些URL是要处理的,也就是爬取的规则:
rules = (
Rule(LinkExtractor(allow=(r'\d+\.html', r'pg\d+\\')), callback='parse_item', follow=True),
)
大家可以打开刚才那个网页中的任意一个房子,观察它的URL。可以发现,URL都是域名加一串数字构成的。如:
http://nj.lianjia.com/ershoufang/103100443605.html。
这里可以用正则表达式写多个规则,我在这里只写了一个。
解析网页
爬虫中的parse_item方法就是用来解析网页,并返回一个item的。
Python有很多解析HTML的优秀库,如BeautifulSoup,我在这里专注于爬虫就不用这些库了。实际上我们可以非常简单地通过XPath语法来获取网页上我们感兴趣的内容。XPath非常简单,只要熟悉CSS选择器就可以快速上手。
我们再来看一下网页的源码,如我们感兴趣的总价:
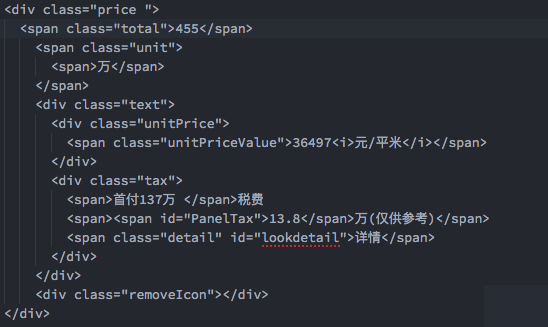
可以看到总价位于class为price的div中的class为total的div中(为看起来方便没有截更多,实际上他们还被class为content的div包含)。
那么要取得总价,XPath写成:
//div[@class="content"]/div[@class="price "]/span[@class="total"]/text()
其他的字段都是类似我就不再赘述。
最终parse_item方法写成:
def parse_item(self, response):
l = ItemLoader(item=HomeLinkItem(), response=response)
l.add_xpath('hid', '//div[@class="content"]/span[@class="sharethis"]/span[@class="erweibox"]/img')
l.add_value('url', response.url)
l.add_xpath('title', '//title/text()')
l.add_xpath('price', '//div[@class="content"]/div[@class="price "]/span[@class="total"]/text()')
l.add_xpath('room', '//div[@class="content"]/div[@class="houseInfo"]/div[@class="room"]'
'/div[@class="mainInfo"]/text()')
l.add_xpath('htype', '//div[@class="content"]/div[@class="houseInfo"]/div[@class="type"]'
'/div[@class="mainInfo"]/text()')
l.add_xpath('area', '//div[@class="content"]/div[@class="houseInfo"]/div[@class="area"]'
'/div[@class="mainInfo"]/text()')
l.add_xpath('areaName', '//div[@class="content"]/div[@class="aroundInfo"]/div[@class="communityName"]'
'/a[@class="info"]/text()')
return l.load_item()
返回一个item。
表的定义
最终我们想把数据保存在数据库中。Scrapy使用SQLAlchemy来帮助完成持久化,它相当于Hibernate,工作原理类似。
定义一个类house来保存数据,它对应数据库表house。sqlalchemy.Column()这句代码定义字段和它的类型等。
在db/下新建house.py:
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class House(Base):
__tablename__ = 'house'
hid = sqlalchemy.Column(sqlalchemy.String, primary_key=True, name='id')
url = sqlalchemy.Column(sqlalchemy.String)
title = sqlalchemy.Column(sqlalchemy.String)
price = sqlalchemy.Column(sqlalchemy.String)
room = sqlalchemy.Column(sqlalchemy.String)
htype = sqlalchemy.Column(sqlalchemy.String, name='type')
area = sqlalchemy.Column(sqlalchemy.String)
areaName = sqlalchemy.Column(sqlalchemy.String, name='area_name')
数据库表house的定义如下:
CREATE TABLE `house` (
`id` varchar(30) NOT NULL DEFAULT '',
`url` varchar(256) DEFAULT NULL,
`title` varchar(200) DEFAULT NULL,
`price` varchar(10) DEFAULT NULL,
`room` varchar(100) DEFAULT NULL,
`type` varchar(100) DEFAULT NULL,
`area` varchar(50) DEFAULT NULL,
`area_name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
这里我使用的是MySQL,打开db/config.py,写入数据库连接字符串:
engine = create_engine('mysql+mysqlconnector://user:pasword@localhost:3306/test')
DBSession = sessionmaker(bind=engine)
保存结果
Pipelines的典型应用就是持久化数据。它接收Spider返回的item对象并对item进行处理。在这里我们把item包装成House类,并持久化。
打开pipelines.py,并加入以下内容:
class DataBasePipeline(object):
def open_spider(self, spider):
self.session = DBSession()
def process_item(self, item, spider):
h = House(
hid=item.get('hid'),
url=item.get('url'),
title=item.get('title'),
price=item.get('price'),
room=item.get('room'),
htype=item.get('htype'),
area=item.get('area'),
areaName=item.get('areaName')
)
self.session.add(h)
self.session.commit()
def close_spider(self, spider):
self.session.close()
open_spider方法取得数据库session。process_item方法处理对象,这里是将House对象存到数据库。
运行爬虫
CD到项目目录,运行命令:scrapy crawl home_link。(home_link是爬虫的名字)
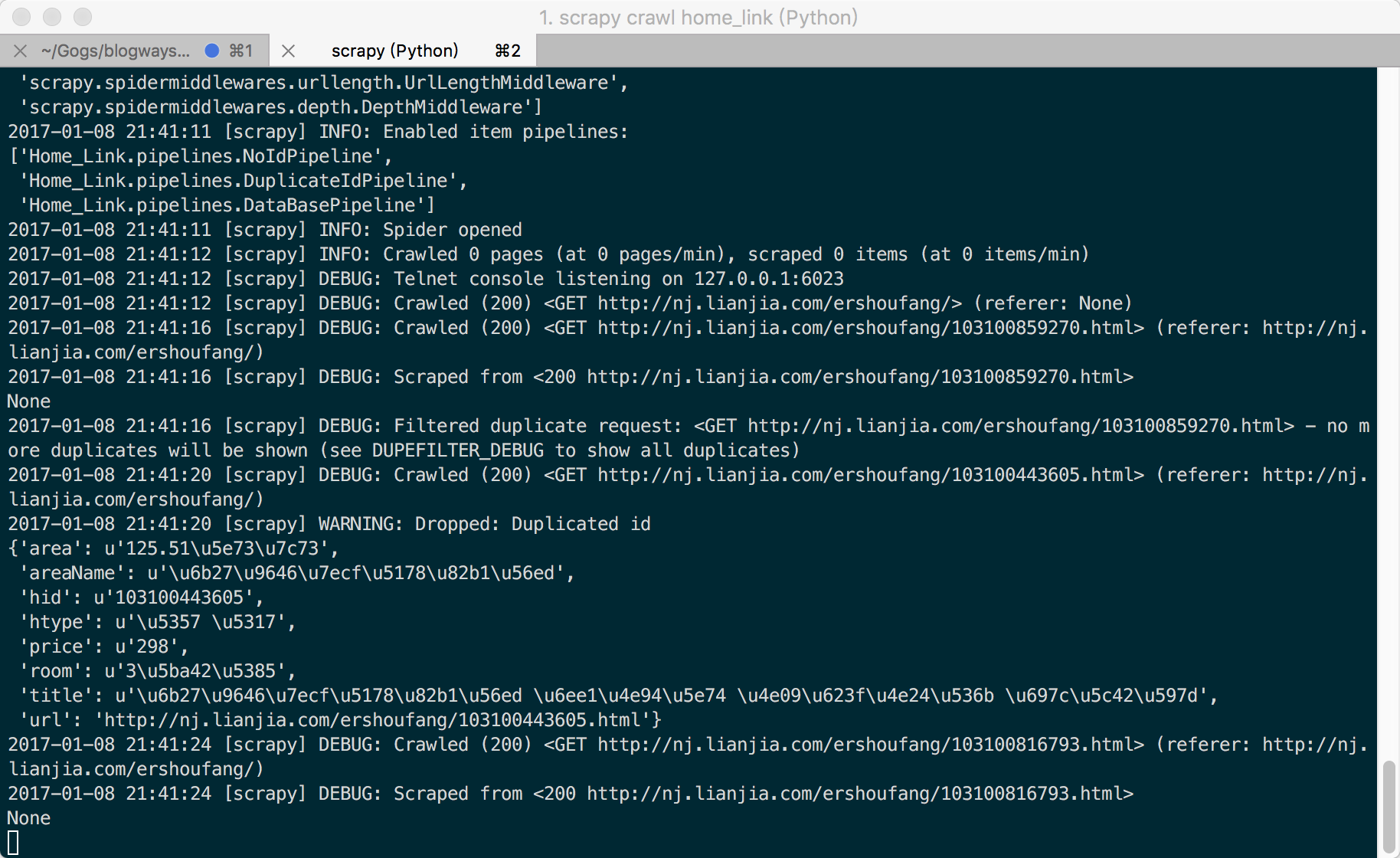
可以看到Scrapy取得了一个house。