Scala速学#
一、Scala简介
Scala是一门现代的多范式编程语言,平滑地集成了面向对象和函数式语言的特性,旨在以简练、优雅的方式来表达常用编程模式。Scala的设计吸收借鉴了许多种编程语言的思想,只有很少量特点是Scala自己独有的。Scala语言的名称来自于“可伸展的语言”,从写个小脚本到建立个大系统的编程任务均可胜任。Scala运行于Java平台(JVM,Java 虚拟机)上,并兼容现有的Java程序,Scala代码可以调用Java方法,访问Java字段,继承Java类和实现Java接口。在面向对象方面,Scala是一门非常纯粹的面向对象编程语言,也就是说,在Scala中,每个值都是对象,每个操作都是方法调用。
Spark的设计目的之一就是使程序编写更快更容易,这也是Spark选择Scala的原因所在。总体而言,Scala具有以下突出的优点: Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统; Scala语法简洁,能提供优雅的API; Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
二、IntelliJ IDEA 安装scala插件
首先在 IDEA 中安装scala插件
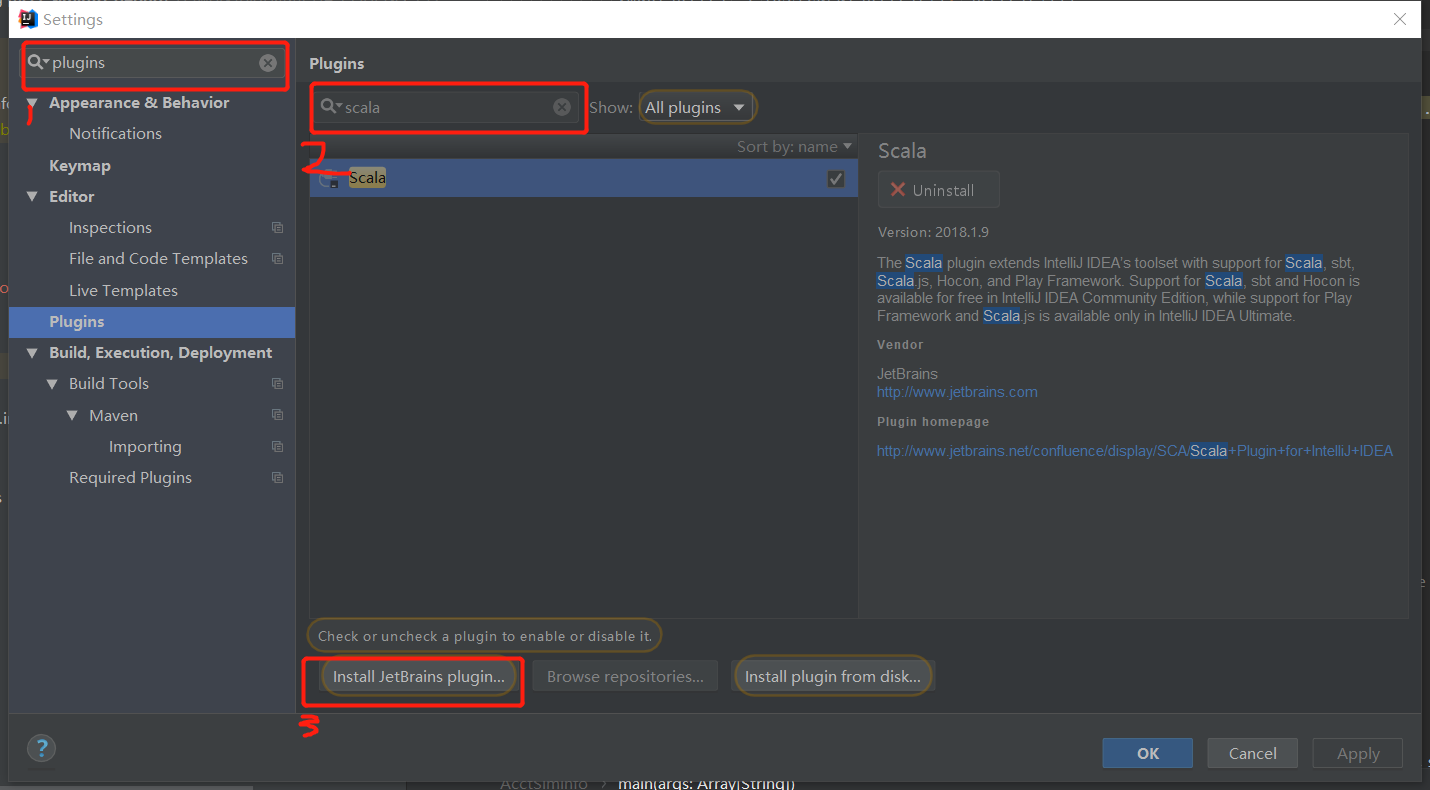
然后下载sdk(选择需要的版本)
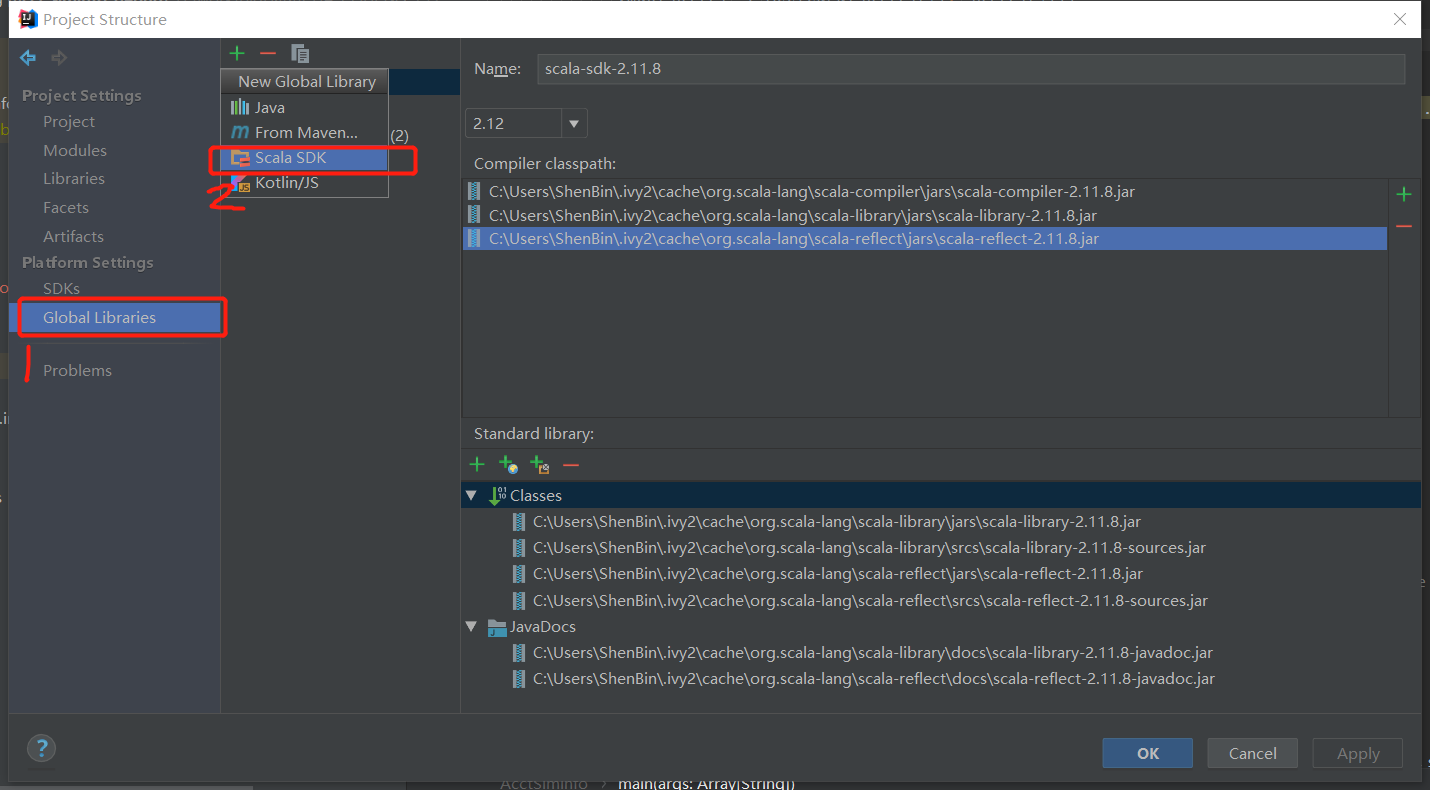
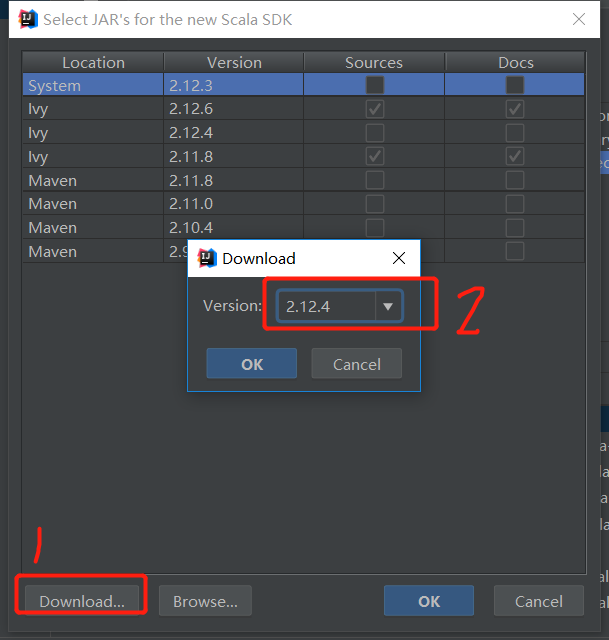
下载完后就可以新建scala项目了,选择jdk和sdk
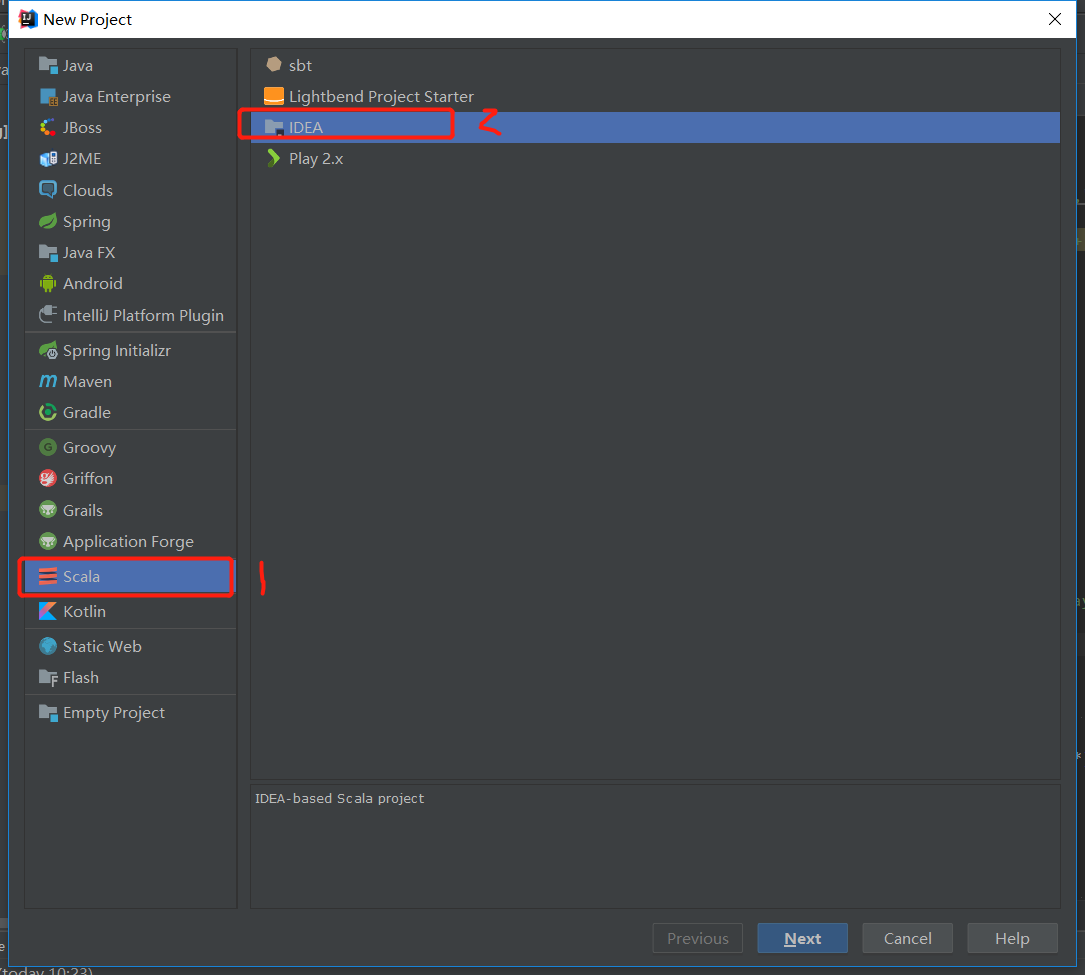
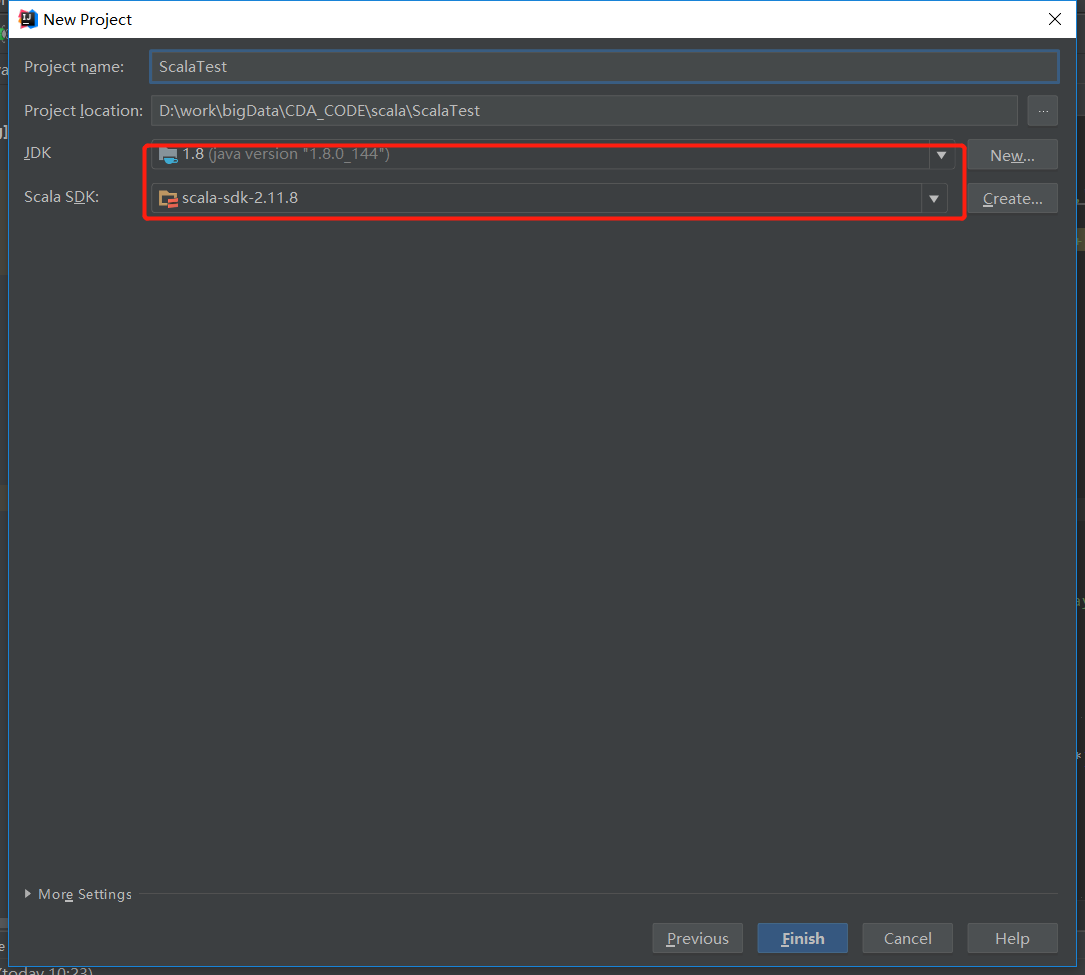
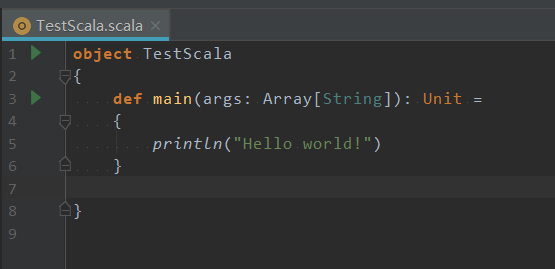
新建一个Object写一个hello world

三、scala基础
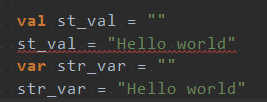
1.申明值和变量
Scala有两种类型的变量,一种是val,是不可变的,在声明时就必须被初始化,而且初始化以后就不能再赋值;另一种是var,是可变的,声明的时候需要进行初始化,初始化以后还可以再次对其赋值。 如下:
2.基本数据类型和操作
Scala的数据类型包括:Byte、Char、Short、Int、Long、Float、Double和Boolean。和Java不同的是,在Scala中,这些类型都是“类”,并且都是包scala的成员,比如,Int的全名是scala.Int。对于字符串,Scala用java.lang.String类来表示字符串
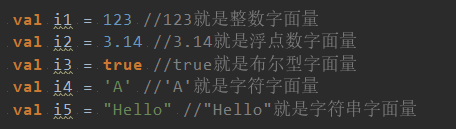
这里要明确什么是“字面量”?字面量包括整数字面量、浮点数字面量、布尔型字面量、字符字面量、字符串字面量、符号字面量、函数字面量和元组字面量。举例如下:
Scala允许对“字面量”直接执行方法,比如:

在Scala中,可以使用加(+)、减(-) 、乘(*) 、除(/) 、余数(%)等操作符,而且,这些操作符就是方法。例如,5 + 3和(5).+(3)是等价的.
需要注意的是,和Java不同,在Scala中并没有提供++和–-操作符,当需要递增和递减时,可以采用如下+= 和-=
3.Range
在执行for循环时,我们经常会用到数值序列,比如,i的值从1循环到5,这时就可以采用Range来实现。Range可以支持创建不同数据类型的数值序列,包括Int、Long、Float、Double、Char、BigInt和BigDecimal等。 写法如下:

4.打印语句
类似c语言,有print , println ,printlnf
写法如下:
5.控制结构
if语句是许多编程语言中都会用到的控制结构。在Scala中,执行if语句和java类似。 写法如下:
if(true){
println(true)
}else{
println(false)
}
Scala中也有和Java类似的while循环语句和for循环语句。 写法如下:
var n = -1
while(n<=0){
println(n)
n+=1
}
for(i <- 1 to 0 by -1){
println(i)
}
6.数据结构
6.1 数组
数组是编程中经常用到的数据结构,一般包括定长数组和变长数组。本教程旨在快速掌握最基础和常用的知识,因此,只介绍定长数组。 定常数组写法如下: val intValueArr = new ArrayInt //声明一个长度为3的整型数组,每个数组元素初始化为0 intValueArr(0) = 12 //给第1个数组元素赋值为12 intValueArr(1) = 45 //给第2个数组元素赋值为45 intValueArr(2) = 33 //给第3个数组元素赋值为33
scala中也有和java类似的List,当然你也可以使用java的List,使用时需要主要类型 写法如下: val list1 = List(1,2,3) //::可以连接元素与List,:::可以连接List与List
val list2 = 0::list1:::list1//结果为ArrayBuffer(0, 1, 2, 3, 1, 2, 3)
println(list2.toBuffer)
val javaList = new util.ArrayList[String]()
javaList.add("1")
javaList.add("2")
6.2 元组
元组是不同类型的值的聚集。元组和列表不同,列表中各个元素必须是相同类型,而元组可以包含不同类型的元素。 写法如下:
val tuple = ("BigData",2015,45.0)
6.3 Set
scala中有类似java中的HashSet的set,写法如下:
var set = Set(1,2,3,3,4)
set += 1
set += 5
println(set.toBuffer)//结果为ArrayBuffer(5, 1, 2, 3, 4)
6.4 Map
scala中也有类似java的Map,写法如下:
var map = Map("1" ->3,"2" -> 2,"3" -> 1)
map += ("4" -> 0)
println(map.toBuffer)//结果为:ArrayBuffer((1,3), (2,2), (3,1), (4,0))
println(map("4"))//结果为:0
6.5 类
scala中也有类似java中的class 的class 写法如下:
class People{
private val secret: String = "xxx"
var name: String = "Jone"
val age: Int = 30
def run(): Unit ={
println(s"${name} is running!")
}
def getSecret(): String ={
secret
}
}
使用时类似java:
val pepple = new People()
pepple.name = "Jack"
pepple.run()//结果为:Jack is running!
println(pepple.getSecret())//结果为xxx
6.6 特质
Java中提供了接口,允许一个类实现任意数量的接口。在Scala中没有接口的概念,而是提供了“特质(trait)”,它不仅实现了接口的功能,还具备了很多其他的特性。Scala的特质,是代码重用的基本单元,可以同时拥有抽象方法和具体方法。Scala中,一个类只能继承自一个超类,却可以实现多个特质,从而重用特质中的方法和字段,实现了多重继承。
特质的定义和类的定义非常相似,有区别的是,特质定义使用关键字trait。 写法如下:
trait CarId{
var id: Int
def currentId(): Int //定义了一个抽象方法
}
上面定义了一个特质,里面包含一个抽象字段id和抽象方法currentId。注意,抽象方法不需要使用abstract关键字,特质中没有方法体的方法,默认就是抽象方法。
特质定义好以后,就可以使用extends或with关键字把特质混入类中。 写法如下:
class BYDCarId extends CarId{ //使用extends关键字
override var id = 10000 //BYD汽车编号从10000开始
def currentId(): Int = {id += 1; id} //返回汽车编号
}
class BMWCarId extends CarId{ //使用extends关键字
override var id = 20000 //BMW汽车编号从20000开始
def currentId(): Int = {id += 1; id} //返回汽车编号
}
###### 6.7 Object Scala并没有提供Java那样的静态方法或静态字段,但是,可以采用object关键字实现单例对象,具备和Java静态方法同样的功能。 下面是单例对象的定义:
object Person {
private var lastId = 0 //一个人的身份编号
def newPersonId() = {
lastId +=1
lastId
}
}
从上面的定义可以看出,单例对象的定义和类的定义很相似,明显的区分是,用object关键字,而不是用class关键字。 假设有一个班级人员管理系统,每当新来一个班级成员,就给分配一个身份编号。当第一个人加入班级时,你就可以调用Person.newPersonId()获得身份编号。
在Java中,我们经常需要用到同时包含实例方法和静态方法的类,在Scala中可以通过伴生对象来实现。当单例对象与某个类具有相同的名称时,它被称为这个类的“伴生对象”。类和它的伴生对象必须存在于同一个文件中,而且可以相互访问私有成员(字段和方法)。 示例如下:
class Person {
private val id = Person.newPersonId() //调用了伴生对象中的方法
private var name = ""
def this(name: String) {
this()
this.name = name
}
def info() { printf("The id of %s is %d.\n",name,id)}
}
object Person {
private var lastId = 0 //一个人的身份编号
private def newPersonId() = {
lastId +=1
lastId
}
def main(args: Array[String]){
val person1 = new Person("Ziyu")
val person2 = new Person("Minxing")
person1.info()
person2.info()
}
}
从上面结果可以看出,伴生对象中定义的newPersonId()实际上就实现了Java中静态(static)方法的功能,所以,实例化对象person1调用newPersonId()返回的值是1,实例化对象person2调用newPersonId()返回的值是2。我们说过,Scala源代码编译后都会变成JVM字节码,实际上,在编译上面的源代码文件以后,在Scala里面的class和object在Java层面都会被合二为一,class里面的成员成了实例成员,object成员成了static成员。
7.模式匹配
Java中有switch-case语句,但是,只能按顺序匹配简单的数据类型和表达式。相对而言,Scala中的模式匹配的功能则要强大得多,可以应用到switch语句、类型检查、“解构”等多种场合。 Scala的模式匹配最常用于match语句中。下面是一个简单的整型值的匹配实例。
val colorNum = 1
val colorStr = colorNum match {
case 1 => "red"
case 2 => "green"
case 3 => "yellow"
case _ => "Not Allowed"
}
println(colorStr)
Scala可以对表达式的类型进行匹配。写法如下:
for (elem <- List(9,12.3,"Spark","Hadoop",'Hello)){
val str = elem match{
case i: Int => i + " is an int value."
case d: Double => d + " is a double value."
case "Spark"=> "Spark is found."
case s: String => s + " is a string value."
case _ => "This is an unexpected value."
}
println(str)
}
8.匿名函数、Lambda表达式
传统类型的函数,定义的语法和我们之前介绍过的定义“类中的方法”类似(实际上,定义函数最常用的方法是作为某个对象的成员,这种函数被称为方法),写法如下:
def counter(value: Int): Int = { value += 1}
函数的也可以作为函数的入参,示例:
def sum(f: Int => Int, a: Int, b: Int): Int ={
if(a > b) 0 else f(a) + sum(f, a+1, b)
} 在调用以上函数时需要传入一个函数,此时便可以传入一个没有定义的匿名函数,示例如下:
var sumValue = sum(a => a+1 ,2, 3)
入参: a => a+1 便是一个匿名函数,这种结构的匿名函数我们经常称为“Lambda表达式”。“Lambda表达式”的形式如下: (参数) => {表达式} //如果参数只有一个,参数的圆括号可以省略,如果表达式只有一行,花括号可以省略
为了让函数字面量更加简洁,我们可以使用下划线作为一个或多个参数的占位符,只要每个参数在函数字面量内仅出现一次。 例如在调用刚才的sum()方法是可以这么写:
var sumValue = sum(_+1 ,2, 3)
9.集合操作
9.1遍历
List,Set,Tuple 等 数据结构最常用的操作就是遍历操作了 List,Set等的遍历都可以用foreach方法遍历,写法如下:
val list = List(1, 2, 3, 4, 5)
list.foreach(elem => println(elem)) //本行语句甚至可以简写为list.foreach(println),或者写成:list foreach println
Map的遍历方法,写法如下:
val mapx = Map (1 ->"a",2 -> "b" ,3 -> "c")
mapx foreach {case(k,v) => println(k+":"+v)}
mapx.foreach( kv => println("key:"+kv._1+",value:"+kv._2) )
mapx foreach {kv => println("key:"+kv._1+",value:"+kv._2)}
9.2map操作
map操作是针对集合的典型变换操作,它将某个函数应用到集合中的每个元素,并产生一个结果集合。 下面有个示例:
val list = List(1, -2, 3, -4, 5)
val list_positive = list.map( v => {
var res = v
if(v<0){
res= -v
}
res
})
println(list_positive.toBuffer)//结果为:ArrayBuffer(1, 2, 3, 4, 5)
flatMap是map的一种扩展。在flatMap中,我们会传入一个函数,该函数对每个输入都会返回一个集合(而不是一个元素),然后,flatMap把生成的多个集合“拍扁”成为一个集合。 示例如下:
val l = List("1,2,3,4","5","6,7,8","9")
val res = l.flatMap(v => v match {
case str:String => str.split(",")
})
println(res.toBuffer)//结果为ArrayBuffer(1, 2, 3, 4, 5, 6, 7, 8, 9) 以上代码会把l的每个元素都进行split然后把结果连成一个list
9.3filter操作
在实际编程中,我们经常会用到一种操作,遍历一个集合并从中获取满足指定条件的元素组成一个新的集合。Scala中可以通过filter操作来实现。 用法如下:
val list = List(1, -2, 3, -4, 5)
val result = list.filter(v => v>0).sum
println(result)//结果为9
以上代码就是把list中所有的大于0 的数进行sum
9.4reduce
在Scala中,我们可以使用reduce这种二元操作对集合中的元素进行归约。 reduce包含reduceLeft和reduceRight两种操作,前者从集合的头部开始操作,后者从集合的尾部开始操作。 写法如下:
val list = List(1, -2, 3, -4, 5)
val result_left = list.reduceLeft(_-_)
val result_right = list.reduceRight(_-_)
println(result_left)//结果为-1
println(result_right)//结果为15
以上代码中,reduceLeft是从list的左侧开始往右进行相减,而reduceRight则是从最右侧开始往左进行相减。