Apache_Kafka入门(二)
前面我们搭建了3个broker的kafka集群 本篇我们介绍一下kafka的一些配置以及java代码,从中学习和理解kafka的一些设计。
一、Producer和Consumer主要配置
我们先来学习一下kafka关于producer和consumer的一些配置,通过配置信息对producer和consumer有个大体了解,同时也是在此做个记录,方便日后使用时查阅。
- Producer主要配置:官方文档
# 用于建立与kafka集群的连接,这个list仅仅影响用于初始化的hosts,来发现全部的servers。
##格式:host1:port1,host2:port2,…,数量尽量不止一个,以防其中一个down了
bootstrap.servers=192.168.127.10:9092,192.168.127.11:9092,192.168.127.12:9092
# Producer用于压缩数据的压缩类型,取值:none, gzip, snappy, or lz4
compression.type=none
# 消息序列化类,默认为kafka.serializer.DefaultEncoder,将消息实体转化为byte[]
serializer.class=kafka.serializer.StringEncoder
# producer接收消息ack的时机,默认为0
# 0:producer不会等待确认,直接添加到socket等待发送;
# 1:这意味着至少要等待leader已经成功将数据写入本地log,但是并没有等待所有follower是否成功写入。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
# all:这意味着leader需要等待所有备份都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。
acks=0
# Producer可以用来缓存数据的内存大小。
##如果数据产生速度大于向broker发送的速度,producer会阻塞max.block.ms,超时则抛出异常
buffer.memory=
# Producer默认会把两次发送时间间隔内收集到的所有Requests进行一次聚合然后再发送,以此提高吞吐量,而linger.ms则更进一步,这个参数为每次发送增加一些delay,以此来聚合更多的Message。
linger.ms=
# 请求的最大字节数。这也是对最大消息大小的有效限制。
# 注意:server具有自己对消息大小的限制,这些大小和这个设置不同。此项设置将会限制producer每次批量发送请求的数目,以防发出巨量的请求。
max.request.size=
# TCP的接收缓存 SO_RCVBUF 空间大小,用于读取数据
receive.buffer.bytes=
# client等待请求响应的最大时间,如果在这个时间内没有收到响应,客户端将重发请求,超过重试次数发送失败
request.timeout.ms=
# TCP的发送缓存 SO_SNDBUF 空间大小,用于发送数据
send.buffer.bytes=
# 指定server等待来自followers的确认的最大时间,根据acks的设置,超时则返回error
timeout.ms=
# 在block前一个connection上允许最大未确认的requests数量。
# 当设为1时,即是消息保证有序模式,注意:这里的消息保证有序是指对于单个Partition的消息有顺序,因此若要保证全局消息有序,可以只使用一个Partition,当然也会降低性能
max.in.flight.requests.per.connection=
# 在第一次将数据发送到某topic时,需先fetch该topic的metadata,得知哪些服务器持有该topic的partition,该值为最长获取metadata时间
metadata.fetch.timeout.ms=
# 连接失败时,当我们重新连接时的等待时间
reconnect.backoff.ms=
# 在重试发送失败的request前的等待时间,防止若目的Broker完全挂掉的情况下Producer一直陷入死循环发送,折中的方法
retry.backoff.ms=
# metrics系统维护可配置的样本数量,在一个可修正的window size
metrics.sample.window.ms=30000
# 用于维护metrics的样本数
metrics.num.samples=2
# 类的列表,用于衡量指标。实现MetricReporter接口
metric.reporters=[]
# 强制刷新metadata的周期,即使leader没有变化
metadata.max.age.ms=300000
# 与broker会话协议,取值:LAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL
security.protocol=PLAINTEXT
# 分区类,实现Partitioner接口
partitioner.class=class org.apache.kafka.clients.producer.internals.DefaultPartitioner
# 控制block的时长,当buffer空间不够或者metadata丢失时产生block
max.block.ms=60000
# 关闭达到该时间的空闲连接
connections.max.idle.ms=540000
# 当向server发出请求时,这个字符串会发送给server,目的是能够追踪请求源
client.id=""
# 发生错误时,重传次数。当开启重传时,需要将`max.in.flight.requests.per.connection`设置为1,否则可能导致失序
retries=0
# key 序列化方式,类型为class,需实现Serializer interface
key.serializer=
# value 序列化方式,类型为class,需实现Serializer interface
value.serializer=
- Consumer主要配置:官方文档
# 用于建立与kafka集群的连接,这个list仅仅影响用于初始化的hosts,来发现全部的servers。
bootstrap.servers=
# 用来唯一标识consumer进程所在组的字符串
group.id=
# 单次拉取的最大消息条数
max.poll.records=
# consumer失效时间,当长时间未收到心跳,并且大于这个时间,broker会将这个consumer从group中移除
session.timeout.ms
# 心跳间隔,需低于session.timeout.ms时间,建议不高于其1/3
heartbeat.interval.ms
# 如果设为true,consumer的offset将在后台定期自动提交
enable.auto.commit
# 当enable.auto.commit设为true时,定期提交的时间间隔(ms)
auto.commit.interval.ms
# 分区策略,取值为range或roundrobin
partition.assignment.strategy
# 自动重置offset,取值earliest、latest、none
# earliest将offset设置为开始位置
# latest将offset设置为开始位置
auto.offset.reset
# 每次最小拉取的消息大小(byte)。Consumer会等待消息积累到一定尺寸后进行批量拉取。默认为1,代表有一条就拉一条
fetch.min.bytes
# 拉取消息的最大值
fetch.max.bytes
# 当消息没有积累到fetch.min.bytes值的最大等待时间
fetch.max.wait.ms
# 元数据刷新时间(无任何改变的情况下)
metadata.max.age.ms
# 每次从单个分区中拉取的消息最大尺寸(byte),默认为1M
max.partition.fetch.bytes
# tcp发送buffer数据的大小,如果值为-1,则为os默认值
send.buffer.bytes
# tcp读取buffer数据的大小,如果值为-1,则为os默认值
receive.buffer.bytes
# 客户端id
client.id
# 连接时间间隔
reconnect.backoff.ms
# 连接失败,重连时间间隔
retry.backoff.ms
# 是否开启CRC32校验,默认为开启
check.crcs
# 指定key的反序列化方式
key.deserializer
# 指定value的反序列化方式
value.deserializer
# 关闭连接的最大空闲时间,默认为540000ms
connections.max.idle.ms
# 客户端等待响应最大时间
request.timeout.ms
# 拦截器列表,默认没有拦截器
interceptor.classes
# 内部topics信息是否可访问,默认为true
exclude.internal.topics
二、通过JAVA代码进入对Kafka的学习
- 构建maven项目,引入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.2.1</version>
</dependency>
2.1 producer 发布消息
- Producer JAVA代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
import java.util.concurrent.Future;
/**
* Created by Gao on 2017/5/13.
*/
public class ProducerDemo {
private Producer<String,String> producer;
private Logger logger= LoggerFactory.getLogger(ProducerDemo.class);
public ProducerDemo() {
//producer配置信息
Properties config=new Properties();
config.setProperty("bootstrap.servers","192.168.127.10:9092,192.168.127.11:9092,192.168.127.12:9092");
config.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
config.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
config.setProperty("acks","0");
producer=new KafkaProducer<String, String>(config);
}
//这里我们并没有指定partit
public void send(String topicName,String message){
if(topicName==null||message==null){
return;
}
//创建消息实体
ProducerRecord<String,String> record=new ProducerRecord<String, String>(topicName,message);
Future<RecordMetadata> future = producer.send(record);
System.out.println("send message ["+message+"] success");
producer.flush();
}
public void close(){
if(producer!=null){
producer.close();
}
}
public static void main(String[] args) {
int i = 1;
while(true) {
new ProducerDemo().send("kafka_study", "hello" + i++);
try {
Thread.sleep(600);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2.1.1 写入方式
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。
2.1.2 消息路由
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
1. 指定了 patition,则直接使用; 2. 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition,通过这样的方案,kafka能够确保相同key值的数据可以写入同一个partition 3. patition 和 key 都未指定,使用轮询选出一个 patition。下面是一些kafka client 对于分区的一些源码片段
//创建消息实例 public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) { if (topic == null) throw new IllegalArgumentException("Topic cannot be null."); if (timestamp != null && timestamp < 0) throw new IllegalArgumentException( String.format("Invalid timestamp: %d. Timestamp should always be non-negative or null.", timestamp)); if (partition != null && partition < 0) throw new IllegalArgumentException( String.format("Invalid partition: %d. Partition number should always be non-negative or null.", partition)); this.topic = topic; this.partition = partition; this.key = key; this.value = value; this.timestamp = timestamp; }private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) { Integer partition = record.partition(); //如果partition不为null就直接使用,如果为null则进行相应计算 return partition != null ? partition : partitioner.partition( record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); }//计算写入的partition。 public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); //如果key为null,轮询选出一个 patition if (keyBytes == null) { int nextValue = nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { // no partitions are available, give a non-available partition return Utils.toPositive(nextValue) % numPartitions; } } else { //KEY不为null则通过对key的keyBytes进行hash计算出一个partition // hash the keyBytes to choose a partition return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }
2.1.3 消息写入流程
- producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后向 leader 发送 ACK
- leader 收到所有 ISR (In-Sync Replicas) 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
2.2 broker 保存消息
2.2.1 存储方式
物理上把 topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),每个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件以及kafka的具体时间日志),单个broker和多个broker的partition略有区别:
-
单个Broker: 创建一个partition为3,Replica为1,Topic名字为kafka_study的topic。我们得到的分布式在配置好的LOG文件夹中生成三个分别为:kafka_study-0、kafka_study-1、kafka_study-2的文件夹用来存储Partition下的信息的.index文件.log文件和.timeindex文件。
-
多个Broker: 创建一个partition为3,Replica为1,Topic名字为kafka_study的topic。我们在Broker0中对应的LOG文件夹中只是发现了kafka_study-0的文件夹,在其他Broker中分别发现了Partition的文件夹。如果Broker数大于Partition数,那么有Broker中没有对应的Partition;如果Broker小于Partition数,Broker中会存在多个Partition。
我们搭建的是三个broker的集群,故partition分布如下图所示:
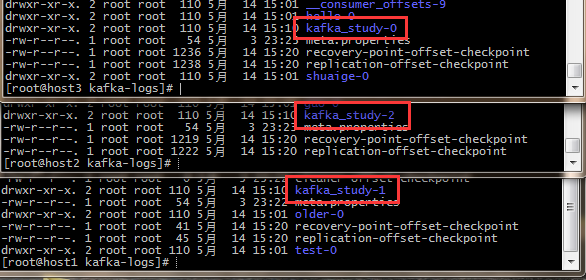
进入partition对应的文件夹可以看到三个文件,如下图:
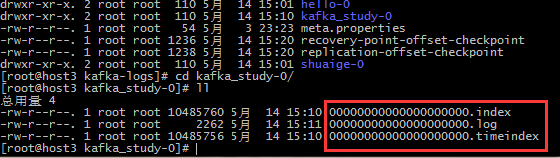
- index文件为索引文件,命名规则为从0开始到,后续的由上一个文件的最大的offset偏移量来开头(19位数字字符长度)
- log文件为数据文件,存放具体消息数据
- timeindex文件,是kafka的具体时间日志
分区算法:
- 分区数=Tt/Max(Tp,Tc)
- Tp:producer吞吐量 Tc:consumer吞吐量 Tt目标的吞吐量
####2.2.2 消息的存储与删除 无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
- 基于时间:log.retention.hours=168
- 基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
###2.3 consumer 消费消息 Kafka 0.10.2.1提供了两套Consumer API共我们使用:
- MockConsumer
- KafkaConsumer
MockConsumer主要供开发测试时使用,这里使用的是KafkaConsumer。
- Consumer JAVA代码
import org.apache.kafka.clients.consumer.*;
import java.util.*;
/**
* Created by Gao on 2017/5/13.
*/
public class ConsumerDemo {
private Consumer<String,String> consumer;
private String topicName;
private String groupId;
public ConsumerDemo(String topicName,String groupId) {
this.topicName=topicName;
this.groupId=groupId;
//consumer配置信息
Properties config=new Properties();
config.setProperty("group.id",groupId);
config.setProperty("bootstrap.servers","192.168.127.10:9092,192.168.127.11:9092,192.168.127.12:9092");
config.setProperty("enable.auto.commit","true");
//设置offset从头开始
config.setProperty("auto.offset.reset","earliest");
config.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
config.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
config.setProperty("auto.commit.interval.ms","60000");
//创建Consumer实例
this.consumer = new KafkaConsumer<String, String>(config);
}
public void receive(){
List<String> topics=new ArrayList<String>();
topics.add(topicName);
//订阅消息
consumer.subscribe(topics);
while (true){
//拉取消息
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String,String> record:records) {
System.out.println(record.toString());
}
System.out.println(records.count());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new ConsumerDemo("kafka_study","test-group").receive();
}
}
####2.3.1 Consumer Group
kafka 的分配单位是 patition。每个 consumer 都属于一个 group,一个 partition 只能被同一个 group 内的一个 consumer 所消费(也就保障了一个消息只能被 group 内的一个 consuemr 所消费),但是多个 group 可以同时消费这个 partition。
####2.3.2 消费方式
consumer 采用 pull 模式从 broker 中读取数据。 push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。 对于 Kafka 而言,pull 模式更合适,它可简化 broker 的设计,consumer 可自主控制消费消息的速率,同时 consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
####2.3.3消息传递保障
现在我们了解一些关于生产者和消费者是如何工作的,接下来我们来讨论kafka提供了生产者和消费者之间的传输语义:官方文档
- At most once 最多一次 — 消息可能丢失,但绝不会重发。
- At least once 至少一次 — 消息绝不会丢失,但有可能重新发送。
- Exactly once 正好一次 — 这是人们真正想要的,每个消息传递一次且仅一次。
如果将 consumer 设置为 autocommit,consumer 一旦读到数据立即自动 commit。如果只讨论这一读取消息的过程,那 Kafka 确保了 Exactly once。
但实际使用中应用程序并非在 consumer 读取完数据就结束了,而是要进行进一步处理,而数据处理与 commit 的顺序在很大程度上决定了consumer delivery guarantee:
- 读完消息 先commit 再处理消息。 这种模式下,如果 consumer 在 commit 后还没来得及处理消息就 crash 了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于 At most once
- 读完消息先处理再 commit。 这种模式下,如果在处理完消息之后 commit 之前 consumer crash 了,下次重新开始工作时还会处理刚刚未 commit 的消息,实际上该消息已经被处理过了。这就对应于 At least once。
- 如果一定要做到 Exactly once,就需要协调 offset 和实际操作的输出。 精典的做法是引入两阶段提交。如果能让 offset 和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,consumer 拿到数据后可能把数据放到 HDFS,如果把最新的 offset 和数据本身一起写到 HDFS,那就可以保证数据的输出和 offset 的更新要么都完成,要么都不完成,间接实现 Exactly once。
参考文章: