JStorm
1.1基本概念
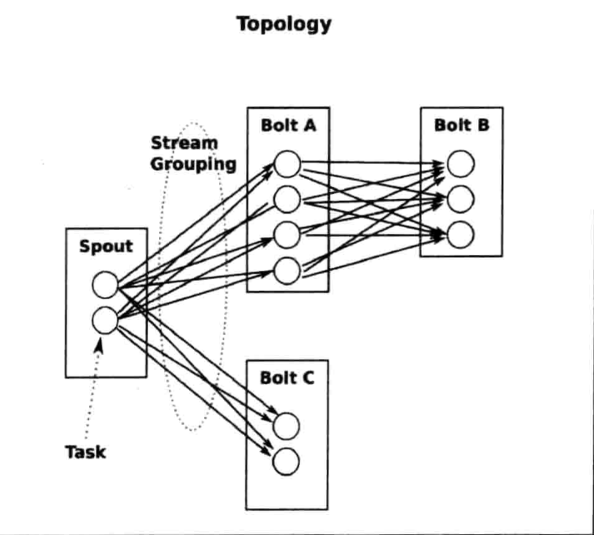
Topology(拓扑):通过Stream Groupings将Spouts和Bolts连接起来构成一个Topology,是Storm中实时应用的一种封装。一个Topology会一直执行,无数据流等待,有数据流执行,知道被kill progress。
Streams(流):消息流Stream是Storm里的关键抽象,一个消息流是一个没有边界的tuple序列,而这些tuple序列会以一种分布式的方式并行地创建和处理。
Spout(数据源):每一个Spout都是一个数据源,通常情况Spout会从外部源读取tuple,并输入到Topology中。Spout可以是可靠的也可以是不可靠的,如果这个tuple没有被Storm成功处理,可靠的消息源可以重新发射,但是不可靠的一旦发出一个tuple就不能重发了。
Bolt(数据处理组件):所有的处理都会在Bolt中被执行,可以做很多事情:过滤、聚合、查询数据库等。Bolt最主要的方法是execute,它以一个tuple作为输入,使用OutputCollector来发射tuple。
Stream groupings(数据流分组):定义一个Topology的每个Bolt接受什么样的流作为输入。Stream Grouping就是用来定义一个Stream应该如何分配数据给Bolt上的多个task。Strom里有7中类型的Stream Grouping。
- Shuffle Grouping:随机分组,随机派发Stream里面的tuple,保证每个Bolt接收到的tuple数目大致相同。
- Fields Grouping:按字段分组,比如按userid分组,相同userid的tuple会被分到同一个Bolt的同一个task中。
- All Grouping:广播发送,对于每一个tuple,所有的Bolt都会收到。
- Global Grouping:全局分组,这个tuple被分配到Storm中的一个Bolt的其中一个task,再具体一点就是分配给id最低的那个。
- Non Grouping:不分组,意思是说Stream不关心到底谁会收到他的tuple。目前这种分组和Shuffle Grouping是一样的效果,有一点不同的是Storm会把这个Bolt放到这个Bolt的订阅者的同一个线程里面去执行。
- Direct Grouping:直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者需要指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法,而且这种消息的tuple必须使用emitDirect方法发射。消息处理这可以通过TopologyContext获取处理它的消息的task的id。
- Local or Shuffle Grouping:如果目标Bolt中有一个或者多个task在同一个工作进程中,tuple将会被随机分配给这些task。否则和普通的Shuffle Grouping行为一直。
Task(任务):每一个Spout和Bolt都会被当作很多task在整个集群里执行。每一个executor对应到一个线程,在这个线程上运行多个task。Stream Grouping是定义怎么从一堆task发射tuple到另一堆task,我们可以调用TopologyBuilder类的setSpout和setBolt来设置并行度,也就是多少个task。
-
并行度:

Worker(工作进程):一个Topology可能会在一个或多个Worker里面执行,每个Worker是一个物理JVM并且执行整个Topology的一部分。
1.2单词计数
public class WordSpout implements IRichSpout{
private String [] sentences = {
"a b c",
"c d e"
};
private int index = 0;
private SpoutOutputCollector collector;
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector = spoutOutputCollector;
}
public void close() {
}
public void activate() {
}
public void deactivate() {
}
public void nextTuple() {
try{
this.collector.emit(new Values(sentences[index]));
index++;
if(index>=sentences.length){
index = 0;
}
}catch (Exception e){
}
}
public void ack(Object o) {
}
public void fail(Object o) {
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentence"));
}
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
WordSpout发出一连串的元组,名字为“sentence”和一个字符串值。比如:{”sentence“:”a b c”}。我们的数据来源是一个String数组,遍历这个数组,发射出每个元组。
public class WordSplit implements IRichBolt{
private OutputCollector collector;
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.collector = outputCollector;
}
public void execute(Tuple tuple) {
try{
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word:words){
this.collector.emit(new Values(word));
}
}catch (Exception e){
}
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word"));
}
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
WordSplit订阅WordSpout的输出对收到的每个元组,进行分割操作,每个单词发射出一个元组:
{”word“:”a“}
{“word”:”b”}
{“word”:”c“}
public class WordCount implements IRichBolt{
private HashMap<String,Long>counts = null;
private OutputCollector collector;
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.collector = outputCollector;
this.counts = new HashMap<String, Long>();
}
public void execute(Tuple tuple) {
try{
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(null == count){
count = 0L;
}
count++;
this.counts.put(word,count);
}catch (Exception e){
}
}
public void cleanup() {
try {
Thread.sleep(10000);
System.out.println("=====================");
for (Map.Entry<String, Long> entry : counts.entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
System.out.println("=======================");
}catch (Exception e){
System.out.print("cleancleancleancleancleanclean");
return;
}
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
WordCount订阅WordSplit的输出,并对相应的单词和出现的次数进行统计。每收到一个元组,就会更新数量,最终打印结果。
public class WordTopology {
public static void main(String[]args) throws InterruptedException {
try {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new WordSpout());
builder.setBolt("split", new WordSplit()).allGrouping("spout");
builder.setBolt("count", new WordCount()).allGrouping("split");
Config config = new Config();
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("topo", config, builder.createTopology());
Utils.sleep(1000);
cluster.killTopology("topo");
cluster.shutdown();
}catch (Exception e){
}
}
}
1.3定时任务
利用系统自带的定时tuple来完成,相当于系统自动发一个带有特殊标记的tuple,然后在bolt中判断,若为此特殊tuple,则执行定时函数。
第一种方法:如果所有的bolt都需要定时,可在topology入口处通过config设置。
第二种方法:如果只有某一类bolt需要定时,可在该bolt内部重写getComponenrConfiguration 方法,在里面设置定时间隔。
public class TopologyTimer01 {
public static class MySpout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
int num = 0;
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.collector = collector;
this.context = context;
}
public void nextTuple() {
num++;
System.out.println("spout:"+num);
this.collector.emit(new Values(num));
Utils.sleep(1000);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
public static class MyBolt extends BaseRichBolt{
private Map stormConf;
private TopologyContext context;
private OutputCollector collector;
int sum = 0;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
public void execute(Tuple input) {
if(input.getSourceComponent().equals(Constants.SYSTEM_COMPONENT_ID)){
System.out.println("时间到了");
}else {
Integer num = input.getIntegerByField("num");
sum += num;
System.out.println("sum="+sum);
}
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
public static void main(String[]args){
TopologyBuilder builder = new TopologyBuilder();
String spout_id = MySpout.class.getSimpleName();
String bolt_id = MyBolt.class.getSimpleName();
builder.setSpout(spout_id,new MySpout());
builder.setBolt(bolt_id,new MyBolt());
Config config = new Config();
config.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS,10);//每隔10秒给topology所有bolt发送一个系统级别的tuple
String topology_name = TopologyTimer01.class.getSimpleName();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(topology_name,config,builder.createTopology());
}
}

public class TopologyTimer02 {
public static class MySpout extends BaseRichSpout {
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
int num = 0;
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.collector = collector;
this.context = context;
}
public void nextTuple() {
num++;
System.out.println("spout:"+num);
this.collector.emit(new Values(num));
Utils.sleep(1000);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
public static class MyBolt1 extends BaseRichBolt{
private Map stormConfig;
private TopologyContext context;
private OutputCollector collector;
public void prepare(Map stormConfig, TopologyContext context, OutputCollector collector) {
this.stormConfig = stormConfig;
this.context = context;
this.collector = collector;
}
public void execute(Tuple input) {
if(input.getSourceComponent().equals(Constants.SYSTEM_COMPONENT_ID)){
System.out.println("MyBolt 01 定时时间到");
}else {
Integer num = input.getIntegerByField("num");
System.out.println("MyBolt 01:" + num);
this.collector.emit(new Values(num));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num01"));
}
@Override
public Map<String,Object> getComponentConfiguration(){
//给当前bolt设置定时任务
HashMap<String,Object>hashMap = new HashMap<String, Object>();
hashMap.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS,10);
return hashMap;
}
}
public static class MyBolt2 extends BaseRichBolt{
private Map stormConfig;
private TopologyContext context;
private OutputCollector collector;
public void prepare(Map stormConfig, TopologyContext context, OutputCollector collector) {
this.stormConfig = stormConfig;
this.context = context;
this.collector = collector;
}
public void execute(Tuple input) {
Integer num = input.getIntegerByField("num01");
System.out.println("MyBolt 02:"+num);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[]args){
TopologyBuilder builder = new TopologyBuilder();
String spout_id = TopologyTimer02.MySpout.class.getSimpleName();
String bolt01_id = TopologyTimer02.MyBolt1.class.getSimpleName();
String bolt02_id = TopologyTimer02.MyBolt2.class.getSimpleName();
String topology_name = TopologyTimer02.class.getSimpleName();
builder.setSpout(spout_id, new MySpout());
builder.setBolt(bolt01_id,new TopologyTimer02.MyBolt1()).shuffleGrouping(spout_id);
builder.setBolt(bolt02_id,new TopologyTimer02.MyBolt2()).shuffleGrouping(bolt01_id);
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(topology_name,config,builder.createTopology());
}
}
1.4系统架构
JStorm系统中有三种不同的Daemon进程:
Nimbus:JStorm中的主控节点,负责接收和验证客户端提交的Topology,分配任务,向ZK写入任务相关的元信息,此外,Nimbus还负责通过ZK来监控节点和任务健康情况,当有Supervisor节点变化或者Worker进程出现问题时及时进行任务重新分配。Nimbus分配任务的结果不是直接下发给Supervisor,也是通过ZK维护分配数据进行过渡。特别地,JStorm 0.9.0领先Apache Storm实现了Nimbus HA(HA指的是双机主备模式,如果主机出现宕机,备用机会顶替上来,从而使整个集群继续工作)。
Supervisor:JStorm中的工作节点,Supervisor类似于MR的TT,subscribe ZK分配到该节点的任务数据,根据Nimbus的任务分配情况启动/停止工作进程Worker。Supervisor需要定期向ZK写入活跃端口信息以便Nimbus及时监控。Supervisor不执行具体的数据处理工作,所有的数据处理工作都交给Worker完成。
Worker:JStorm中任务执行者,Worker类似于MR的Task,所有实际的数据处理工作最后都在Worker内执行完成。Worker需要定期向Supervsior汇报心跳,由于在同一节点,同时为保持节点的无状态,Worker定期将状态信息写入本地磁盘,Supervisor通过读本地磁盘状态信息完成心跳交互过程。Worker绑定一个独立端口,Worker内所有单元共享Worker的通信能力。
