Spark简单教学#
一、Spark简介
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(即Hadoop、Spark、Storm)。
Spark具有如下几个主要特点:
- 运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
- 容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
- 运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
二、Spark运行架构
Spark架构的组成图如下:
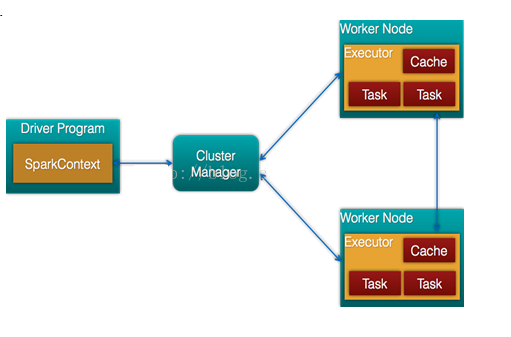
- Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
- Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
- Driver: 运行Application 的main()函数
- Executor:执行器,是为某个Application运行在worker node上的一个进程
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
Spark的基本运行流程如下:
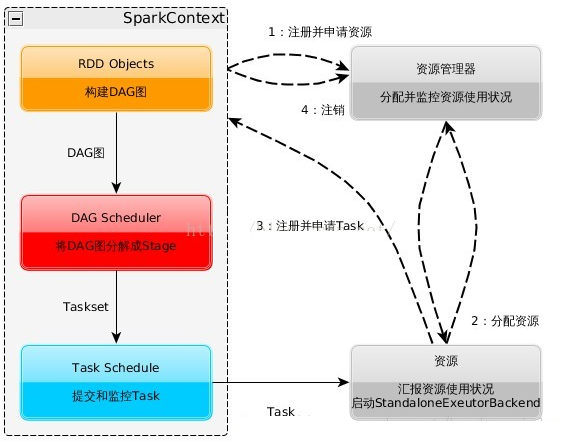
- 当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;
- 资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;
- SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
- 任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
三、RDD
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
四、 使用IntelliJ IDEA编写Spark应用程序(Scala+Maven)
使用IntelliJ IDEA编写scala程序需要安装scala插件和sdk,安装方法可以参考另一篇博文:Scala速学。
在有了scala插件和sdk之后,便可以新建一个maven项目,pom文件中可以使用依赖:
<properties>
<spark.version>2.1.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
导入依赖后可以新建一个测试类WordCount.scala测试能否正常调试,测试类代码如下: import org.apache.spark.sql.SparkSession
object WordCount
{
def main(args: Array[String]): Unit =
{
val spark = SparkSession.builder()
.master("local") //本地模式
.appName("WordCount")
.getOrCreate()
val result = spark.read.textFile("file:///D:/Test/test.txt") //读取的文件,支持正则如test.*
.rdd
.flatMap(line => line.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.collect()
println(result.toBuffer)
}
}
进行debug,会启动单机模式的spark,运行结果如下:
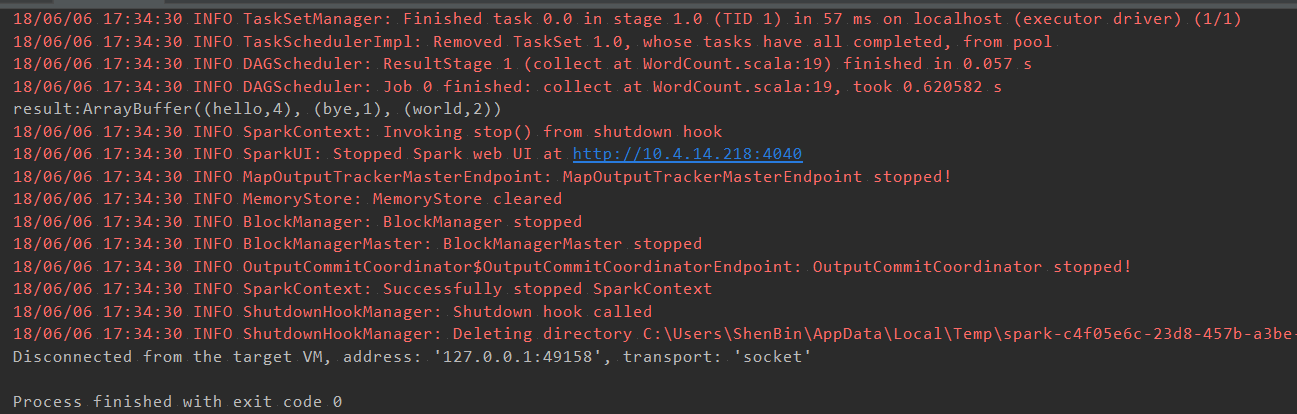
到此就能进行spark程序的开发了。
五、Spark编程基础
1.读写文件
除了可以对本地文件系统进行读写以外,Spark还支持很多其他常见的文件格式(如文本文件、JSON、SequenceFile等)和文件系统(如HDFS、Amazon S3等)和数据库(如MySQL、HBase、Hive等)。数据库的读写将在Spark SQL部分介绍,这里只介绍hdfs文件系统的读写和不同文件格式的读写。
本地文本文件可以使用textFile()函数进行读取,用法如下: val spark = SparkSession.builder() .master(“local”) //本地模式 .appName(“WordCount”) .getOrCreate()
val result = spark.read.textFile("file:///D:/Test/test.txt") //读取的文件,支持正则如test.*
.rdd
.flatMap(line => line.split(" "))
result.saveAsTextFile("file:///D:/Test/out.txt")
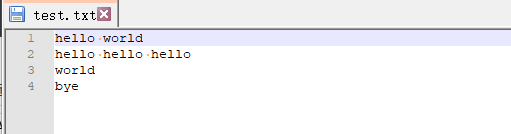
test.txt文件内容如下:
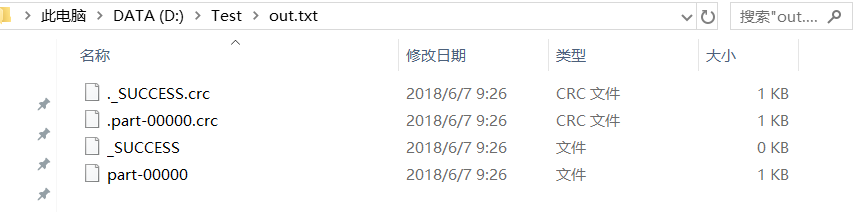
运行以上代码之后会在D盘Test文件夹下生成一个out.txt 文件夹,内容如下:
查看part-00000文件,内容如下:
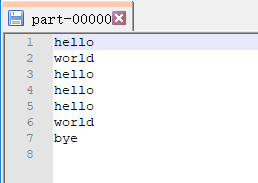
可以发现part-00000文件中的内容为程序的预期结果,那如果想要再次把数据加载到RDD时候要使用该文件吗?其实不需要,只要使用spark.read.textFile(“D:\Test\out.txt”)刚才生成的文件夹即可。
分布式文件系统HDFS数据读取和本地文件相同只需指定hdfs地址,代码如下:
val spark = SparkSession.builder()
.master("local") //本地模式
.appName("WordCount")
.getOrCreate()
val result = spark.read.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
六、SparkSQL
6.1 SparkSQL 简介
Spark SQL是Spark生态系统中非常重要的组件,其前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目于2014年开始停止开发,转向Spark SQL。Spark SQL全面继承了Shark,并进行了优化。
Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以来自Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。从Spark1.2 升级到Spark1.3以后,Spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API。
Spark SQL可以很好地支持SQL查询,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询。
6.2 SparkSQL使用
SparkSQL可以把DataFrame当作临时表,只需使用sql语句便可完成对数据的操作。
要使用DataFrame需要引入隐式转换:
val spark = SparkSession.builder()
.master("local") //本地模式
.appName("WordCount")
.getOrCreate()
import spark.implicits._//隐式转换
val result = spark.read.textFile("hdfs://localhost:9000/user/hadoop/word.txt") //读取的文件,支持正则如test.*
.rdd
.flatMap(line => line.split(" "))
.toDF()
result.createOrReplaceTempView("tf_f_word")
spark.sql("select * from tf_f_word").show()
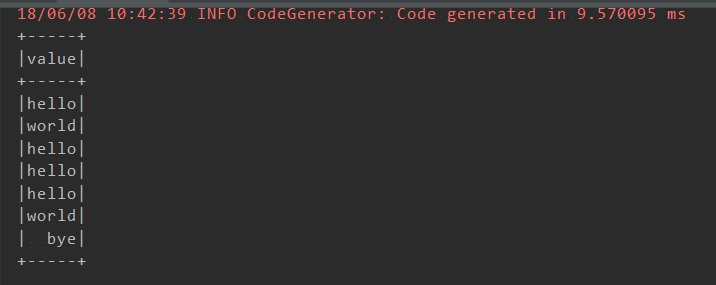
引入隐式转换后便可将RDD转换成DataFrame,调用createOrReplaceTempView 方法可将数据作为临时表使用sql语句进行操作。以上代码结果如下:
上面把每行数据都为string,直接转换为DataFrame是没有定义字段名的,当然你可以为他定义字段名,不过还有更简单的方法,把数据map成case class即可,代码如下:
case class Word(word:String,count:Int)
def main(args: Array[String]): Unit =
{
val spark = SparkSession.builder()
.master("local") //本地模式
.appName("WordCount")
.getOrCreate()
import spark.implicits._//隐式转换
val result = spark.read.textFile("file:///D:/Test/test.txt") //读取的文件,支持正则如test.*
.rdd
.flatMap(line => line.split(" "))
.map(word => Word(word,1))
.toDF()
result.createOrReplaceTempView("tf_f_word")
spark.sql("select * from tf_f_word").show()
spark.sql("select word,sum(count) as wordCounts from tf_f_word group by word").show()
}
代码结果如下:
tf_f_word 的内容:
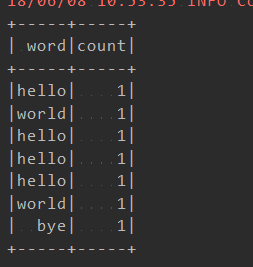
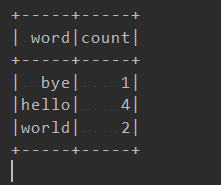
计数结果:
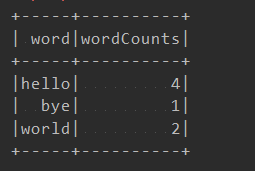
6.3 连接数据库
在计算完后许多时候需要把计算结果存储到数据库,DataFrame可以非常方便的存入数据库,代码如下:
import java.util.Properties
import org.apache.spark.sql.{SaveMode, SparkSession}
object WordCount
{
case class Word(word:String,count:Int)
def main(args: Array[String]): Unit =
{
val spark = SparkSession.builder()
.master("local") //本地模式
.appName("WordCount")
.getOrCreate()
import spark.implicits._//隐式转换
val result = spark.read.textFile("file:///D:/Test/test.txt") //读取的文件,支持正则如test.*
.rdd
.flatMap(line => line.split(" "))
.map(word => Word(word,1))
.toDF()
result.createOrReplaceTempView("tf_f_word")
spark.sql("select * from tf_f_word").show()
val wordCounts = spark.sql("select word,sum(count) as count from tf_f_word group by word")
val properties = new Properties()
properties.put("user", "root")//数据库连接用户名密码
properties.put("password", "root")
Class.forName("com.mysql.jdbc.Driver").newInstance()//加载jdbc
wordCounts.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/db","tf_f_word_counts",properties)//写入数据库
}
}
运行以上代码,会将处理结果插入本地数据库db库中的tf_f_word_counts表中,表中数据如下:
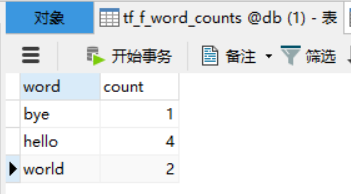
有时我们也需要从数据库中读取数据,sprkSQL可以直接把表读取成DataFrame,代码如下:
val spark = SparkSession.builder()
.master("local") //本地模式
.appName("WordCount")
.getOrCreate()
import spark.implicits._//隐式转换
val properties = new Properties()
properties.put("user", "root")//数据库连接用户名密码
properties.put("password", "root")
Class.forName("com.mysql.jdbc.Driver").newInstance()//加载jdbc
val table = spark.read.jdbc("jdbc:mysql://localhost:3306/db","tf_f_word_counts",properties)//查询数据库
table.show()
以上代码便能读取刚刚存入数据库的tf_f_word_counts表,运行结果如下: