一、分片介绍
分片是一个遍及多台机器存储数据的方法,MongoDB 使用分片来实现对大数据集合部署与高吞吐量操纵的支持。
分片的目的
对一个单一数据库系统服务来说,大数据集合和高吞吐量的应用程序将会是一个非常严峻的考验。高的查询速率会“吃光”服务器的所有CPU,更大的数据集合超出一个单一机器的存储空间。最后,工作集合的大小比系统内存容量( 磁盘驱动的I/O性能 )大。
解决上诉问题的方式有两个:
- 纵向扩展 ( vertical scaling )
- 分片 ( sharding )
Vertical scaling,增加更多的CPU数和存储资源来增加容纳量,但是扩展存在限制:更多核心数的CPU和更多RAM的高性能系统比更小的系统昂贵,而且其 CPU 和 RAM 的增加与得到的性能不是曾比例的。另外,云服务提供商可能只允许用户提供更小的例子。因此,纵向扩展存在一个性能的最大极限。
Sharding,或者说是水平扩展,相反地将大数据集合拆分并将数据分布到多个服务器,或分片上。每个分片都是一个独立的数据库,所有的分片组成一个逻辑数据库。
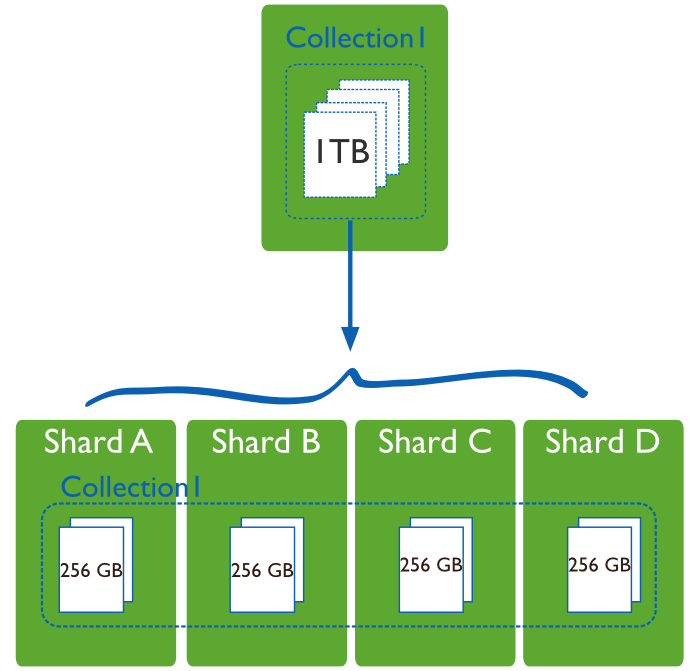
分片地址扩展到支持高吞吐率和大数据集合的难点:
- 分片降低了每个分片处理操作的数量,随着集群的增长,每个分片将会处理更少的操作。其结果是,一个集群能够水平地增加容纳量和高吞吐量。例如:插入数据时,应用程序只需要访问负责该记录的碎片。
- 分片减少了每个服务器需要存储的数据量,随着集群的增长,每个分片将会保存更少的数据。例如:一个数据库有 1TB 的数据,分4个分片后,每个分片只要保存 256GB 的数据;如果有40个分片的话,每个分片只需要保存 25GB 的数据。
二、MongoDB 分片
MongoDB 支持通过配置一个分片集群来支持分片。
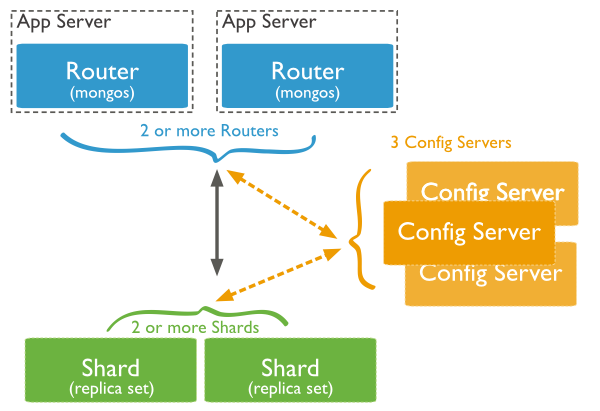
分片集群由分片、查询路由和配置服务器三个组件构成:
- Shards 用于保存数据。为了提供高可用性和数据一致性,在一个生产环境分片集群中,每个分片都有一个复制集( Replica Set )。关于复制集更多的信息,见Replica Sets
- Query Routers,或者说
mongos实例,客户端应用程序操作的接口,直接操作合适的分片或分片集。查询路由处理并将操作定位到分片,然后将结果返回给客户端。一个分片集群能够包含多个查询路由( Query Router ),用以分担客户端请求的负载。一个客户端和一个查询路由一一对应,更多的分片集群需要很多的查询路由。 - Config Server 保存集群的元数据( metadata ),包含集群数据集到分片的映射,查询路由通过元数据将操作定位到指定的分片上。生产环境下,拥有确切的 3个配置服务器。
数据分割
MongoDB 在集合的水平上分割数据和分片,通过一个分片键( shard key )来分割分片。
分片键( Shard Keys )
为了将一个集合分片,需要选择一个分片关键字。一个分片关键字是一个索引字段,或存在于每个集合文档中的一个复合索引字段。MongoDB 按分片字段将集合划分为块( chunks ),然后讲所有的块均匀的分布到所有分片上。为了划分集合为区块,MongoDB 提供了范围分片(Range Based Sharding) 和 哈希分片(Hash Based Sharding)。
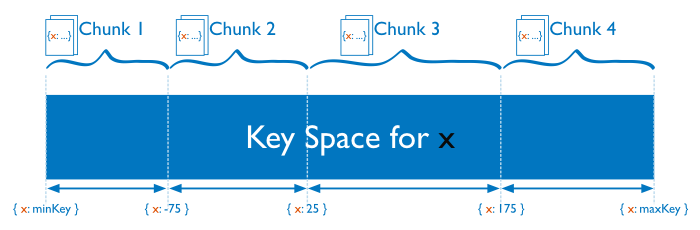
范围分片( Range Based Sharding )
在范围分片中,MongoDB 通过范围划分字段值提供的范围分割,将数据集合划分为不同的范围边界。就像一个数字分片字段:将负无穷到正无穷的所有数形象化为一条线,每个分片字段的值都落在该线上的某个点上。此线段被 MongoDB 划分为的更小的,没有重叠的范围叫做块( chunks ),一个块是某最小值到某最大值之间值的范围。
已知的一个范围分割系统,分片字段值“相近”的文档分布在同一个块上,因此也在同一个分片上。
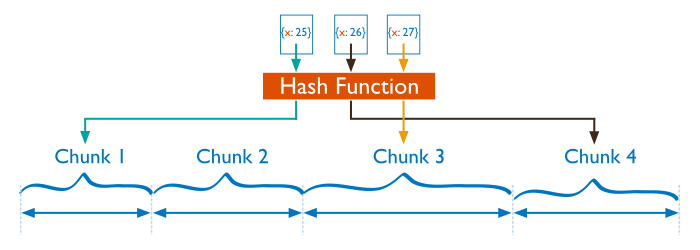
哈希分片( Hash Based Sharding )
在哈希分片中,MongoDB 计算一个字段值的哈希值,然后使用此哈希值创建一个区块。
如果使用哈希分割,分片字段值“相近”的两个文档可能不在同一个区块中,这确保了一个集合在集群中更大限度的随机分布。
范围分片和哈希分片的性能差异
基于范围的分片方式提供了更高效的范围查询,给定一个片键的范围,分发路由可以很简单地确定哪个数据块存储了请求需要的数据,并将请求转发到相应的分片中。
不过,基于范围的分片会导致数据在不同分片上的不均衡,有时候,带来的消极作用会大于查询性能的积极作用。比如,如果片键所在的字段是线性增长的,一定时间内的所有请求都会落到某个固定的数据块中,最终导致分布在同一个分片中。在这种情况下,一小部分分片承载了集群大部分的数据,系统并不能很好地进行扩展。
与此相比,基于哈希的分片方式以范围查询性能的损失为代价,保证了集群中数据的均衡。哈希值的随机性使数据随机分布在每个数据块中,因此也随机分布在不同分片中。但是也正由于随机性,一个范围查询很难确定应该请求哪些分片,通常为了返回需要的结果,需要请求所有分片。
使用标记自定义集群中数据的分布
MongoDB允许管理员使用 Tag Aware Sharding 直接决定集群的均衡策略。管理员使用标记与片键的范围做绑定,并将标记与分片直接绑定,之后,均衡器会将满足标记的数据直接分发到与之绑定的分片上,并且确保之后满足标记的数据一直存储在相应的分片上。
标记是控制均衡器行为和数据块分布的首要条件,一般来讲,在拥有多个数据中心时,才会使用标记自定义集群中数据块的分布,以提高不同地域之间数据访问的效率。
参考 Tag Aware Sharding 获得更多相关信息。
数据分布均衡的维护
新数据的加入或者新分片的加入可能会导致集群中数据的不均衡,即表现为有些分片保存的数据块数目显著地大于其他分片保存的数据块数。
MongoBD使用两个过程维护集群中数据的均衡:
-
分裂;
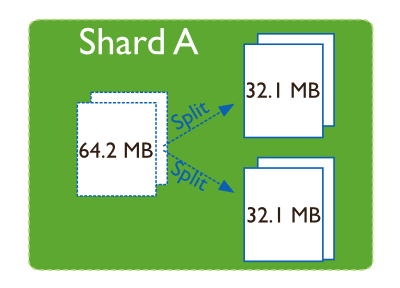
分裂是防止某个数据块过大而进行的一个后台任务。当一个数据块的大小超过设定的数据块大小时,MongoDB会将其一分为二,插入与更新触发分裂过程。分裂改变了元信息。但是效率很高,进行分裂时,MongoDB 不会迁移任何数据,对集群性能也没有影响。
-
均衡器。
均衡器是一个管理区块迁移的后台进程,均衡器在一个集群中所有的查询路由上运行。
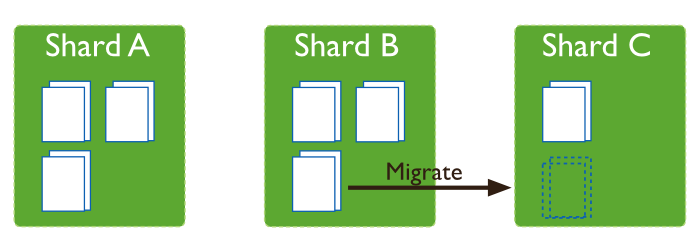
当集群中数据的不均衡发生时,均衡器会将数据块从数据块数目最多的分片迁移到数据块最少的分片上,举例来讲:如果集合 users 在 shard1 上有100个数据块,在 shard2 上有50个数据块,均衡器会将数据块从 shard1 一直向 shard2 迁移,一直到数据均衡为止。
分片管理在后台管理从 源分片 到 目标分片 的数据块迁移,在迁移过程中,目标分片首先会接收源分片在迁移数据块上的所有数据,之后,目标分片应用在上一迁移步骤之间发生在源分片上的迁移数据块的更改,最后,存储在配置服务器 上的元信息被更新。
如果迁移中发生错误,源分片上的数据不会被修改,迁移会停止。在迁移成功结束之后MongoDB才会在源分片上将数据删除。
在集群中增加或者删除分片
在集群中增加分片时,由于新的分片上并没有数据块,会造成数据的不均衡。此时MongoDB会立即开始向新分片迁移数据,集群达到数据均衡的状态需要花费一些时间。
当删除一个分片时,均衡器需要将被删除的分片上的数据全部迁移到其他分片上,在全部迁移结束且元信息更新完毕之后,你可以安全地将这个分片移除。