一、背景
实时采集主机的日志文件,发送到 node.js 处理程序( 暂时叫做 load ),经过一些数据处理后插入到 MongoDB 持久存储。由于采集的主机数量较多,导致了如下问题:
- 每秒需要入库的数据量很大,单个 MongoDB 无法满足这些数据的入库要求,导致插入的拥堵,导致 MongoDB 中的不是实时的数据;
- MongoDB 缓存到内存中的热数据量太多,单台主机无法满足如此大的内存需求;
- MongoDB 持久化存储到本地磁盘的数据非常大( 有些表一天的数据量有上千万条 ),需要的存储空间很大,单台无法满足要求。
考虑到纵向扩展的代价较高,决定采用 MongoDB 的分片机制来实现,需要探究的问题:
- 单个 MongoDB 实例的入库速率极限是多少;
- load( 处理接收到的日子文件,并入库到MongoDB )的数量与入库速率的关系;
- 分片的片数与入库速率的关系;
- 单台主机( 8核心,16G )启动load和 MongoDB 实例的最合适个数;
二、测试单个MongoDB入库极限
启动一个 MongoDB 实例,分别测试启动多个load时,MongoDB的入库速率( 10min中入库的记录条数 ),发往load的日子数量充足;
MongoDB 实例启动:
mongod --dbpath /data/mongodb/db --logpath /data/mongodb/logs/mongod.log --nojournal --fork 具体命令吃处不在讲解,详见[MongoDB 安装与分布式部署](http://www.blogways.net/blog/2015/05/04/mongodb-install-and-distribution-deploy.html)
测试结果
| load 个数 | 十分钟入库数 | 入库速率( 条/sec ) |
|---|---|---|
| 1 | 222902 | 372 |
| 2 | 260933 | 435 |
| 3 | 259581 | 433 |
| 4 | 260966 | 435 |
结论
针对当前load 应用处理程序,单个 MongoDB 实例的入库极限速度为:435 条/sec。
注意
- 测试中还记录并且计算了其它时间长度的入库速度,有一些差异,但都在误差的范围内;
- 针对不同的处理入库逻辑,测出的入库极限速度都不同,本内容的所有数据都是基于自己的load,仅供参考。
三、分片数与入库速率的关系( python )
考虑到日志的抓去、load的处理和数据入库中间存在很多的不确定性,因而首先只选择测试每秒钟插入记录数来表面存在的关系。
测试方案
分别在 3 台不同的主机上部署3个配置服务器(Config Server),在其中的一台上面部署 3 个查询路由(Query Router),最后在另一台主机上( 不包含在部署Config Server 和 Query Router主机内 ),分别启动1、2、3、4个分片(按照 host字段,Hash 分片);
通过ruby语言编写插入记录程序( 需要pymongo插件 ),部分代码如下:
#!/bin/env python
from pymongo import MongoClient
import time,datetime,random
# 启动的3个查询路由
db1 = MongoClient('10.20.16.78:27017').test
db2 = MongoClient('10.20.16.78:27018').test
db3 = MongoClient('10.20.16.78:27019').test
def insert(num):
for i in range(num):
rand = random.randint(1,3)
host = random.randint(1,3)
if rand == 1:
db = db1
elif rand == 2:
db = db2
else:
db = db3
obj = {
"host": host,
# 生成插入的对象
}
db.objInsert.insert_one(obj)
insert(300000) 上面的每个脚本表示插入 300000 条记录到分片表中,此处为测试分三片时候的入库速率;
配置
将test.objInsert表按照host字段哈希分片:
sh.shardCollection('test.objInsert', {'host': 'hashed'}) 启动`python`脚本向数据库插入数据,记录10s、1min的插入速率。
测试数据
应该很多次测试,此处只贴出一次结果:
| 分片 片数 | 10s入库数 | 入库速率( 条/sec ) |
|---|---|---|
| 1 (不分片) | 120263 | 12026 |
| 2 | 148543 | 14854 |
| 3 | 185022 | 18502 |
绘制的平滑标记散点连线图,如下所示:
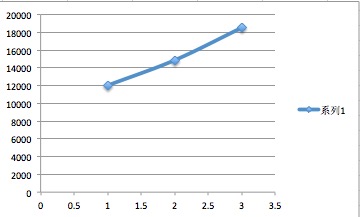
结论
由上图可得到一个大概的猜想:入库速率与分片片数呈线性关系!
注意
由于主机数、主机内存等愿意的限制,没法启动太多的python脚本用于数据插入,实际测试用用的两台机器来插入测试;
测试主机还有其它程序占用CPU等,没法长时间处于python脚步执行状态,测试只记录 10s 中的数据;还有可能涉及到其它原因,长时间插入会出现速率波动;
四、入库速度与load数量的关系
由于 node.js 连接 MongoDB 的所有数据库操作都是异步调用的,所以很多操作只能在回调函数中进行,或通过其它方式将其转换为同步操作( 如:async、EventProxy )。
在测试的初期,发现有时候load占用的内存会不断的升高,有时候甚至会导致load程序崩溃,后来实验发现,是因为MongoDB 的入库速率达到了瓶颈,而又有不断的数据插入,导致回掉函数无法立即执行并积压在内存中,是的占用内存越来越高,最后程序崩溃。
根据上述原因,可以通过load的内存占用来侧面反应load和MongoDB的工作状态:
- 内存占用过高,load对接收到的日志处理不过来,或MongoDB的入库速率到达极限;
- 内存占用正常或稍微偏高( 10 ~ 100M之内 ),load和 MongoDB都处在比较理想的工作状态;
- 内存占用偏低,load或 MongoDB的性能部分处于闲置状态。
在做本项测试的时候,需要保证 MongoDB的出来能力能满足所有load个数的限制,观察不同个数时的入库记录条数;因而在必要的时候需要启动多个分片;
测试方案
分别启动1、2、3、4个load,并启动相应的分片数( 使得每个load的内存占用正常 ),启动3个配置服务器;考虑到多个load的情况,传递过来的日子数据通过nginx按 响应时间 做负载均衡处理。
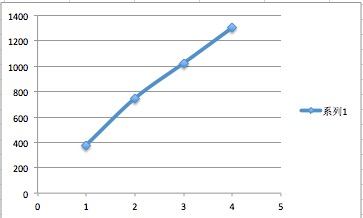
测试数据
| load 个数 | 10min入库数 | 入库速率( 条/sec ) |
|---|---|---|
| 1 | 227079 | 379 |
| 2 | 447980 | 747 |
| 3 | 614332 | 1024 |
| 4 | 782492 | 1304 |
绘制的平滑标记散点连线图,如下所示:
多次测量的过程中,load的内存占用都在100 ~ 250 M之间,CPU 占用率100%左右( 完全占用一个物理CPU核心 )。
结论
- 由上图可发现,load个数和入库速率所呈现的基本是一条直线,因而得到结论load的个数与入库速率成线性关系;
- 由于load在正常工作情况下内存占用补不超过300M,这相对于一台主机的16G的内存来说很小,因而一台机器能启动的load的个数取决于其核心数,还要留一些用作它用,因而8核心CPU主机,启动 4 ~ 7个load是比较合适的。
注意
- 在测试4个load的时候,开始使用了3个配置服务器,4个分片,结果每个load的内存占用都高达600M以上,说明分4片没法满足4个load的入库请求;
- 然后使用3个配置服务器,6个分片,load的内存占用在400M以上,同样6个分片也无法满足要求;
- 最后在启用8个分片后,内存占用降到了100M多一点,说明此时的MongoDB的处理入库速度完全够4个load使用。
五、分片数与入库速率的关系( load )
有测试四的注意可知,4个load,3个配置服务器即可完成测试不分片、分2、3、4片时的入库速率。
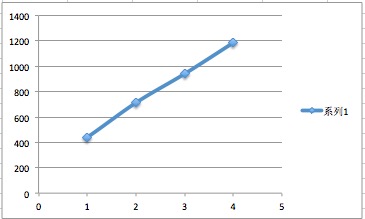
测试数据
| 分片 片数 | 20min入库数 | 入库速率( 条/sec ) |
|---|---|---|
| 不分片 | - | 435 |
| 2 | 854605 | 712 |
| 3 | 1127365 | 940 |
| 4 | 14220( 2min ) | 1185 |
绘制的平滑标记散点连线图,如下所示:
每个mongod进程( 分片实例 )的CPU占用在繁忙的时候会接近100%,有时候甚至超过100%;
结论
- 由上图可知,分片的片数与入库速率亦是成线性关系;
- 由于CPU会超过100%的考虑,单台8核心的服务器,最多启动6个分片;
注意
- 单台主机的MongoDB 分片的片数选择主要考虑 CPU 的核心数;
- MongoDB 分片进程会讲插入的数据都保存到内存中,直到内存完全被耗光,后续的数据会持久化到磁盘空间,内存中只会保存热数据和索引。
- 如果主机内存吃紧的话,启动分片实例的时候最好带
--nojurounal启动。
六、总结
- load 的个数和入库速率成线性关系;
- MongoDB 分片的片数和入库速率成线性关系;
- 单台主机启动load的个数主要考虑因素是 CPU 核心数,最多启动
n - 2 (n 为 cpu 核心数)个; - 单台主机启动MongoDB 分片实例的个数,参考因素为 CPU 核心数,最多启动
n - 2 (n 为 cpu 核心数)个;
</br> </br>
===
后续修改中。。。