| 目 录 | |
|---|---|
| 1 | 基本原理 |
| 2 | 索引类型 |
| 3 | 索引方式 |
| 4 | 注意事项 |
一、基本原理
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。
当数据保存在磁盘类存储介质上时,它是作为数据块存放。这些数据块是被当作一个整体来访问的,这样可以保证操作的原子性。硬盘数据块存储结构类似于链表,都包含数据部分,以及一个指向下一个节点(或数据块)的指针,不需要连续存储。
记录集只能在某个关键字段上进行排序,所以如果需要在一个无序字段上进行搜索,就要执行一个线性搜索的过程,平均需要访问N/2的数据块,N是表所占据的数据块数目。如果这个字段是一个非主键字段(也就是说,不包含唯一的访问入口),那么需要在N个数据块上搜索整个表格空间。
但是对于一个有序字段,可以运用二分查找,这样只要访问log2(N)的数据块。这就是为什么性能能得到本质上的提高。
二、索引类型
Normal(普通索引)
最基本的索引,没有任何限制。索引长度必须是固定的,MySQL所允许的最大索引长度是255个字符。
Unique(唯一索引)
与普通索引的不同就是索引列的值必须唯一,但允许有空值。
(1)单列唯一索引。
(2)主键索引,是一种特殊的唯一索引,不允许有空值。
(3)组合索引,多列组合成一个索引,组合值必须唯一。
Full Text(全文检索)
普通索引只能加快字段内容开头字符的检索,如果字段是多个单词构成 的较大段文字,普通索引就没什么作用。 这种检索往往以LIKE %word%的形式出现,如果需要处理的数据量很大,响应时间就会很长。 MySQL将把在文本中出现的所有单词创建为一份清单,查询操作将根据这份清单去检索有关的数据记录。
三、索引方式
1.Hash方式
Hash 索引就是把这一列进行哈希算法计算,得到哈希值,排序在哈希数组上,索引的检索可以一次定位。 其效 率很高,不像BTree 索引需要从根节点到枝节点,所以 Hash 索引的查询效率要远高于 BTree 索引。

(1)不能使用hash索引排序。
(2)Hash索引不支持键的部分匹配,因为是通过整个索引值来计算hash值的。
(3)Hash索引只支持等值比较查询,如:=,in(),<=精确查询。对于WHERE age>20并不能加速查询。
2.BTree方式
Btree索引是以B+树为存储结构实现的,但是Btree索引的存储结构在Innodb和MyISAM中有很大区别。 MyISAM的索引方式也称为非聚集,Innodb的索引方式成为聚集索引。
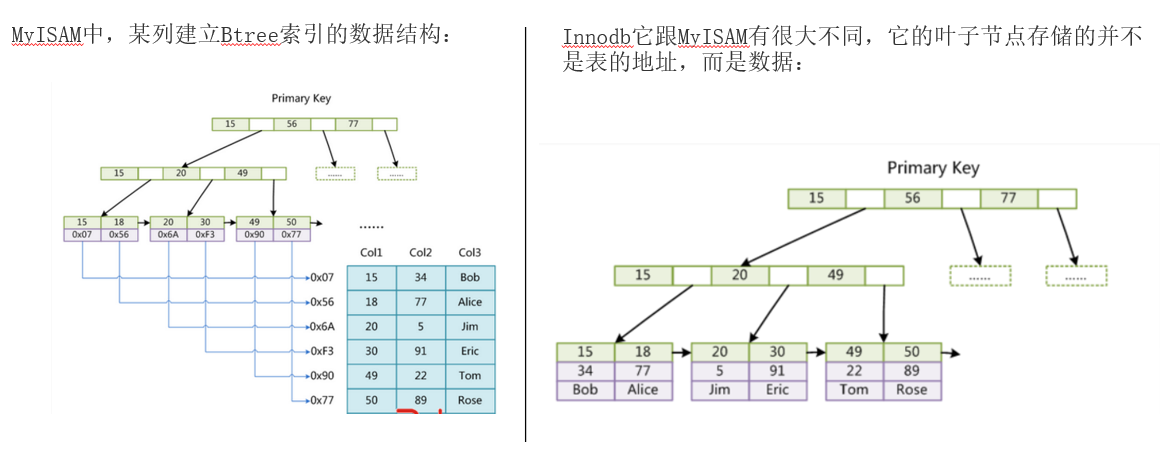
存储引擎-MyIsAM和InnoDB的区别
(1)MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。
(2)MyISAM是表级锁,而InnoDB是行级锁。
(3)InnoDB不支持FULLTEXT类型的索引,不保存表的具体行数。
(4)MyISAM表不支持外键
(5)对于自增长类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
因此,当你的数据库有大量的写入、更新操作而查询比较少或者数据完整性要求比较高的时候就选择InnoDB表。当你的数据库主要以查询为主,相比较而言更新和写入比较少,并且业务方面数据完整性要求不那么严格,就选择MyISAM表。因为MyISAM表的查询操作效率和速度都比InnoDB要快。
四、注意事项
数据库能同时使用多个索引
SELECT * FROM TB WHERE A=5 AND B=6
能分别使用索引(A) 和 (B);
对于这个语句来说,创建组合索引(A,B) 更好;
最终是采用组合索引,还是两个单列索引?主要取决于应用系统中是否存在这类语句:
SELECT * FROM TB WHERE B=6
SELECT * FROM TB WHERE A=5 OR B=6
组合索引(A, B)不能用于此查询,很明显,分别创建索引(A) 和 (B)会更好;
删除无效的冗余索引
TB表有两个索引(A, B) 和 (A),对应两种SQL语句:SELECT * FROM TB WHERE A=5 AND B=6 和 SELECT * FROM TB WHERE A=5
执行时,并不是WHERE A=5 就用 (A); WHERE A=5 AND B=6 就用 (A, B);
其查询优化器会使用其中一个以前常用索引,要么都用(A, B), 要么都用 (A)。
所以应该删除索引(A),它已经被(A, B)包含了,没有任何存在的必要。
使用场景需要注意:
(1) 频繁的作为查询条件的字段应该创建为索引。
(2) 唯一性很差的字段不适合做索引(如:性别),因为就算建立了索引,二叉树也就只有一层,还是要大规模的进行表的扫描。
(3) 更新很频繁的字段不适合作为索引,因为每次操作的时候都会遍历,修改或者删除索引,这样会降低更新表的速度。
(4) 在列中有复合索引时,只要查询条件有使用最左边的列,索引一般就会被使用到。
复合索引:alter table dept add index my_index(dname,loc);//dname是左边的列。(5) 模糊查询 like ‘%a’(%为前缀)、not in、<>条件 不会用到索引,’a%’(%为后缀)会用到索引。
(6) 索引的数据类型越小越简单越好,整型数据比起字符,处理开销更小。
(7) 只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
(8) 不要在列上进行函数运算,如select * from users where YEAR(xxdate)<2007;应该写为:select * from users where xxdate<’2007-01-01’;