| 目 录 | |
|---|---|
| 1 | Storm简介 |
| 2 | Storm集群的组成 |
| 3 | Storm基本概念 |
| 4 | Storm流分组 |
一、Storm简介
Storm是什么?
Storm是一个开源的分布式实时计算系统,它提供了一系列的基本元素用于进行计算:Topology(拓扑)、Stream、Spout、Bolt等等。
Storm的解决的是什么?
在Storm之前,实时计算的实现用的是标准队列和worker的方法。比如, 我们向一个队列集合里面写入data, 再用worker从这个队列集合读取data并处理他们。 通常情况下这些worker需要通过另一个队列集合向另一个worker集合发送消息来进一步处理这些data。
我们非常不满意这种处理方式,这种方法不稳定–我们必须要保证所有的队列和worker一直处于工作状态,并且在构建应用时它也显得很笨重。 应用的大部分逻辑都集中在从哪发送/获取信息和怎样序列化/反序列化这些消息等等。但是在实际的业务逻辑里面它只是代码库的一小部分。再加上一个应用的正确逻辑应该是可以跨多个worker,并且这些worker之间是可以独立部署的,一个应用的逻辑也应该是自我约束的。
Storm通过对 之前需要处理的繁重工作-发送/接收消息,序列化,部署等 这些操作的抽象实现了自动化。
二、Storm集群的组成
Storm集群里有两种节点: 控制节点和工作节点。控制节点上运行一个叫Nimbus后台程序,Nimbus负责在集群里面分发代码,分配计算任务给机器和监控状态。工作节点上运行一个叫做Supervisor的进程,Supervisor监听分配到机器的任务,根据需要启动/关闭工作进程worker。
每一个工作进程执行一个topology的一个子集,一个运行的topology由运行在很多机器上的很多工作进程worker组成。(一个supervisor里面有多个workder,可以配置worker的数量,对应的是conf/storm.yaml中的upervisor.slot的数量)
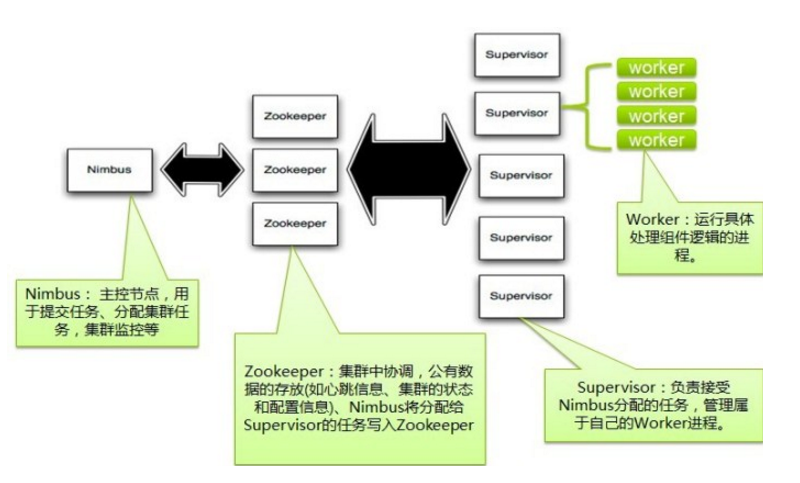
Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成,除此之外,Nimbus后台程序和Supervisor后台程序是快速失效和无状态的。所有的状态保持在Zookeeper中或者是本地磁盘中,这意味着你能关闭Nimbus或者Supervisor而他们将会再次启动就像什么事情都没有发生过一样,这个设计使得Storm异常的稳定。
三、Storm基本概念
数据流Topology
在Storm中,一个实时应用的计算任务被打包作为Topology发布,Topology任务一旦提交后永远不会结束,除非你显示去停止任务。计算任务Topology是由不同的Spouts和Bolts,通过数据流(Stream)连接起来的图。
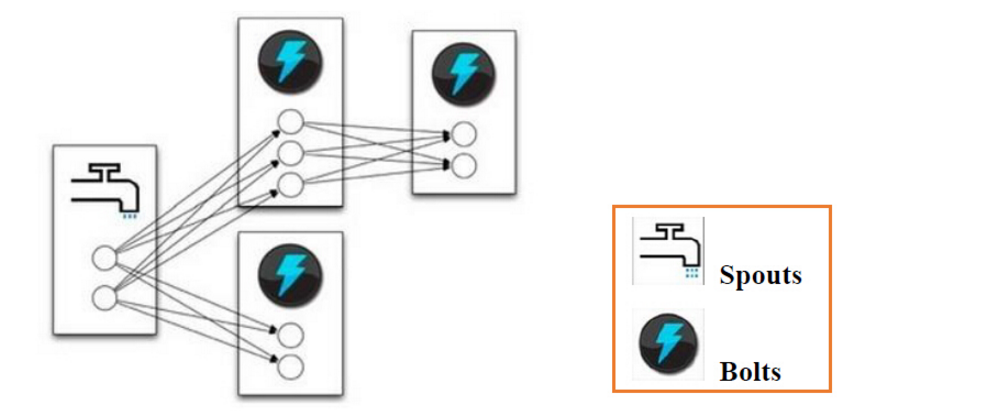
其中包含有:
Spout:Storm中的消息源,用于为Topology生产消息(数据),一般是从外部数据源(如Message Queue、RDBMS、NoSQL、Realtime Log )不间断地读取数据并发送给Topology消息(tuple元组)。
Bolt:Storm中的消息处理者,用于为Topology进行消息的处理,Bolt可以执行过滤,聚合,查询数据库等操作,而且可以一级一级的进行处理。
数据模型Tuple
Storm使用tuple来作为它的数据模型,每个tuple是一堆有名字的值,每个值可以是任何类型,可以理解为一个tuple是一个java对象。如果使用自定义类型来作为值类型,需要对值类型进行序列化。
一个Tuple代表数据流中的一个基本的处理单元,它可以包含多个Field,每个Field表示一个属性。如:三个字段(taskID:int; StreamID:String; ValueList: List):
Worker上执行的Task
worker中每一个spout/bolt的线程称为一个task,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
Storm的记录级容错
相比于其他实时计算系统,Storm最大的亮点在于其记录级容错和能够保证消息精确处理的事务功能。Storm中记录级容错的意思是,Storm会告知用户每一个消息单元是否在指定时间内被完全处理了。如下图:
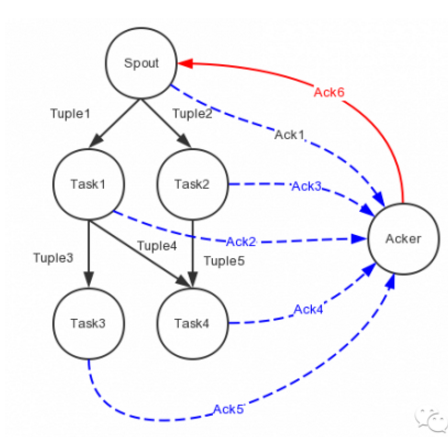
在Storm的topology中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败了,相反则会告知spout该消息处理成功了。
Storm的事务拓扑
事务拓扑简单来说就是将消息分为一个个的批(batch),同一批内的消息以及批与批之间的消息可以并行处理,另一方面,用户可以设置某些bolt为committer,storm可以保证committer的finishBatch()操作是按严格不降序的顺序执行的。用户可以利用这个特性通过简单的编程技巧实现消息处理的精确。
四、Storm流分组
Stream Grouping定义了一个流在Bolt任务间该如何被切分,就是哪个Task来处理哪些数据,按什么规则来分配。
Storm提供的6种类型:
随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“color”字段,相同“color”的元组总是分发到同一个任务,不同“color”的元组可能分发到不同的任务。
全部分组(All grouping):tuple被复制到bolt的所有任务,广播方式。
全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。
直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。