应用场景
批量入库适用于实时性要求不是很高,但一批入库数据量很大的情况。
有时候批量数据类型并不都是文件类型,比如:计费流程中从Kafka获取到的list
mysql批量入库语法
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name.txt'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[FIELDS
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char' ]
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number LINES]
[(col_name_or_user_var,...)]
[SET col_name = expr,...)]
该处主要讲解一下LOCAL关键字的含义,其他不做讲解。
如果指定了LOCAL,则被认为与连接的客户端有关:
1.如果指定了LOCAL,则文件会被客户主机上的客户端读取,并被发送到服务器。文件会被给予一个完整的路径名称,以指定确切的位置。如果给定的是一个相对的路径名称,则此名称会被理解为相对于启动客户端时所在的目录。
2.如果LOCAL没有被指定,则文件必须位于服务器主机上,并且被服务器直接读取。
当在服务器主机上为文件定位时,服务器使用以下规则:
1)如果给定了一个绝对的路径名称,则服务器使用此路径名称。
2)如果给定了带有一个或多个引导组件的相对路径名称,则服务器会搜索相对于服务器数据目录的文件。
3)如果给定了一个不带引导组件的文件名称,则服务器会在默认数据库的数据库目录中寻找文件。
1.IGNORE忽略 情形
使用IO流的方式直接将流数据导入mysql
批量入库源码
/**
* 批量导入mysql
* @param conn 数据库连接
* @param tableName 数据库表名
* @param dataList 数据
* @param coverType 覆盖类型
* @param fieldSplit 字段分隔符
* @param fields 如:(field1, field3) 定义导入字段
* @param SQLException 设定文件
* @return void 返回类型
*/
public static void loadFile(Connection conn, String tableName, List<String> dataList, String coverType, String fieldSplit, String fields) throws SQLException {
StringBuffer loadDataSql = new StringBuffer();
loadDataSql.append("LOAD DATA LOCAL INFILE 'sql.csv' ");
loadDataSql.append(coverType);
loadDataSql.append(" INTO TABLE ");
loadDataSql.append(tableName);
loadDataSql.append(" FIELDS TERMINATED BY '");
loadDataSql.append(fieldSplit);
loadDataSql.append("' LINES TERMINATED BY '");
loadDataSql.append(lineSplit);
loadDataSql.append("' ");
loadDataSql.append(fields);
System.out.println(loadDataSql.toString());
conn.setAutoCommit(false);
PreparedStatement pt = conn.prepareStatement(loadDataSql.toString());
com.mysql.jdbc.PreparedStatement sqlStatement = null;
if (pt.isWrapperFor(com.mysql.jdbc.Statement.class)) {
sqlStatement = pt.unwrap(com.mysql.jdbc.PreparedStatement.class);
}
StringBuilder sb = new StringBuilder();
for(String line : dataList){
sb.append(line);
sb.append(lineSplit);
}
byte[] bytes = sb.toString().getBytes();
InputStream in = new ByteArrayInputStream(bytes);
sqlStatement.setLocalInfileInputStream(in);
int rows = sqlStatement.executeUpdate();
try {
sqlStatement.close();
in.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("importing "+rows+" rows data into mysql ");
}
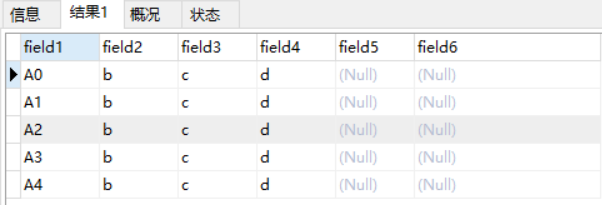
(1)【操作】 针对4个字段的批量入库,field1为tb_test表的主键
Connection conn = CdrDBMgr.getConnection("xx");
List<String> dataList = new ArrayList<String>();
for(int i=0;i<5;i++){
String s = "A"+i+",b,c,d";
dataList.add(s);
}
String fieldSql = "(field1,field2,field3,field4)";
System.out.println(DataStore2.storeCdr(conn, "tb_test", dataList, fieldSql));
【SQL】 LOAD DATA LOCAL INFILE ‘sql.csv’ IGNORE INTO TABLE tb_test FIELDS TERMINATED BY ‘,’ LINES TERMINATED BY ‘’ (field1,field2,field3,field4)
【结果】
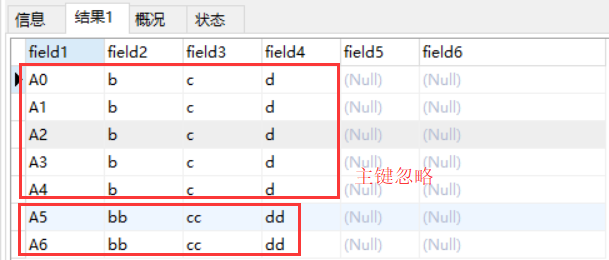
(2)【操作】 修改 for(int i=0;i<7;i++)…String s = “A”+i+”,bb,cc,dd”; 预期结果是已有数据不会变化,新插入两条数据
【结果】
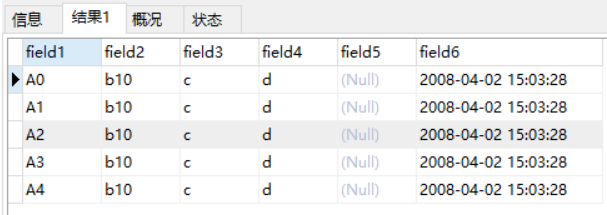
(3)【操作】 修改 String fieldSql = “(field1,@2,field3,field4,@5) set field2=concat(@2,10),field6=str_to_date(@5,’%Y-%m-%d %H:%i:%s’)”;
【SQL】 LOAD DATA LOCAL INFILE ‘sql.csv’ IGNORE INTO TABLE tb_test FIELDS TERMINATED BY ‘,’ LINES TERMINATED BY ‘ ‘ (field1,@2,field3,field4,@5) set field2=concat(@2,10),field6=str_to_date(@5,’%Y-%m-%d %H:%i:%s’)
【结果】
2.REPLACE覆盖 情形
使用IO流的方式直接将流数据导入mysql
(1)【操作】 针对4个字段的批量入库,field1为tb_test表的主键
Connection conn = CdrDBMgr.getConnection("xx");
List<String> dataList = new ArrayList<String>();
for(int i=0;i<3;i++){
String s = "A"+i+",b,c,d,2008-4-2 15:3:28,f,g";
dataList.add(s);
}
String fieldSql = "(field1,field2,field3,field4)";
System.out.println(DataStore2.replaceCdr(conn, "tb_test", dataList, fieldSql));
【SQL】 LOAD DATA LOCAL INFILE ‘sql.csv’ REPLACE INTO TABLE tb_test FIELDS TERMINATED BY ‘,’ LINES TERMINATED BY ‘’ (field1,field2,field3,field4)
【结果】 [ WARN] batch storage failure: Row 1 was truncated; it contained more data than there were input columns
说明:使用关键字时,入库数据字段必须与定义的数据库字段个数一致,否则报错
上面问题修改 String fieldSql = “(field1,@2,field3,field4,@5,@6,@7)”;
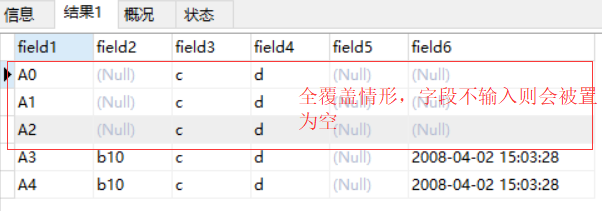
原因分析:
从打印的日志看 importing 6 rows data into mysql,入库了3条记录但是数据库执行了6次,实际上REPLACE情形下是通过先delete后再执行insert的方法,所以不导入的字段会变为空,这一点使用时需要特别注意。
3.UPDATE更新 情形
**批量入库源码 **
/**
* 批量更新mysql
* @param conn 数据库连接
* @param tableName 数据库表名
* @param dataList 数据
* @param fields 如:(field1, field3) 定义更新字段
* @param SQLException 设定文件
* @return void 返回类型
*/
public static void loadFile(Connection conn, String tableName, List<String> dataList, String fields) throws SQLException {
StringBuffer loadDataSql = new StringBuffer();
loadDataSql.append("insert into ");
loadDataSql.append(tableName);
loadDataSql.append(fields);
loadDataSql.append(" values ");
for(int i=0;i<dataList.size();i++){
loadDataSql.append("(");
loadDataSql.append(dataList.get(i));
loadDataSql.append(")");
if(i != dataList.size()-1){
loadDataSql.append(",");
}
}
loadDataSql.append(" on duplicate key update ");
loadDataSql.append(" field2=values(field2), field3=values(field3), field4=values(field4)");
System.out.println(loadDataSql.toString());
conn.setAutoCommit(false);
PreparedStatement pt = conn.prepareStatement(loadDataSql.toString());
System.out.println(pt.execute());
}
(1)【操作】 针对4个字段的批量入库,field1为tb_test表的主键
Connection conn = CdrDBMgr.getConnection("xx");
List<String> dataList = new ArrayList<String>();
for(int i=0;i<5;i++){
String s = "'A"+i+"','bxx','cxx','dxx'";
dataList.add(s);
}
String fieldSql = "(field1,field2,field3,field4)";
System.out.println(DataStore2.updateCdr(conn, "tb_test", dataList, fieldSql));
【SQL】
insert into tb_test(field1,field2,field3,field4) values
('A0','bxx','cxx','dxx'),
('A1','bxx','cxx','dxx'),
('A2','bxx','cxx','dxx'),
('A3','bxx','cxx','dxx'),
('A4','bxx','cxx','dxx')
on duplicate key update field2=values(field2), field3=values(field3), field4=values(field4)
【结果】
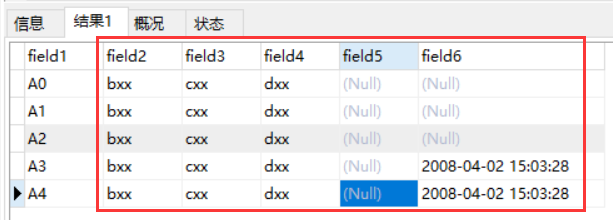
原有的字段field6中有两行值并没有被置为空,可以满足业务需要,但该方法效率比REPLACE略慢,需要结合情形使用。
另外:
-- 可以只更新部分字段
insert into tb_test(field1,field2,field3,field4)
values ('A0','b1','c1','d1'),('A1','b1','c1','1')
on duplicate key update field2=values(field2)
-- 同样支持函数表达式
insert into tb_test(field1,field2,field3,field4)
values ('A0','b11','c11','2008-4-1 15:3:21'),('A1','b1','c1','2008-4-2 15:3:26')
on duplicate key update field2=values(field2), field3=values(field3), field6=str_to_date(values(field4),'%Y-%m-%d %H:%i:%s')