应用场景
JStorm处理数据的方式是基于消息的流水线处理,因此特别适合无状态计算,也就是计算单元的依赖的数据全部在接收的消息中可以找到,并且最好一个数据流不依赖另外一个数据流。
因此,常常用于
-
日志分析,从日志中分析出特定的数据,并将分析的结果存入外部存储器如数据库。
-
管道系统,将一个数据从一个系统传输到另外一个系统,比如将数据库同步到Hadoop。
-
消息转化器,将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件。
-
统计分析器,从日志或消息中,提炼出某个字段,然后做count或sum计算,最后将统计值存入外部存储器。中间处理过程可能更复杂。
现有storm无法满足的一些需求:
-
现有的storm调度太粗暴简单,无法定制化
-
雪崩问题一直没有解决
-
监控太简单
-
对ZK访问太频繁
JStorm比Storm更稳定,更快!
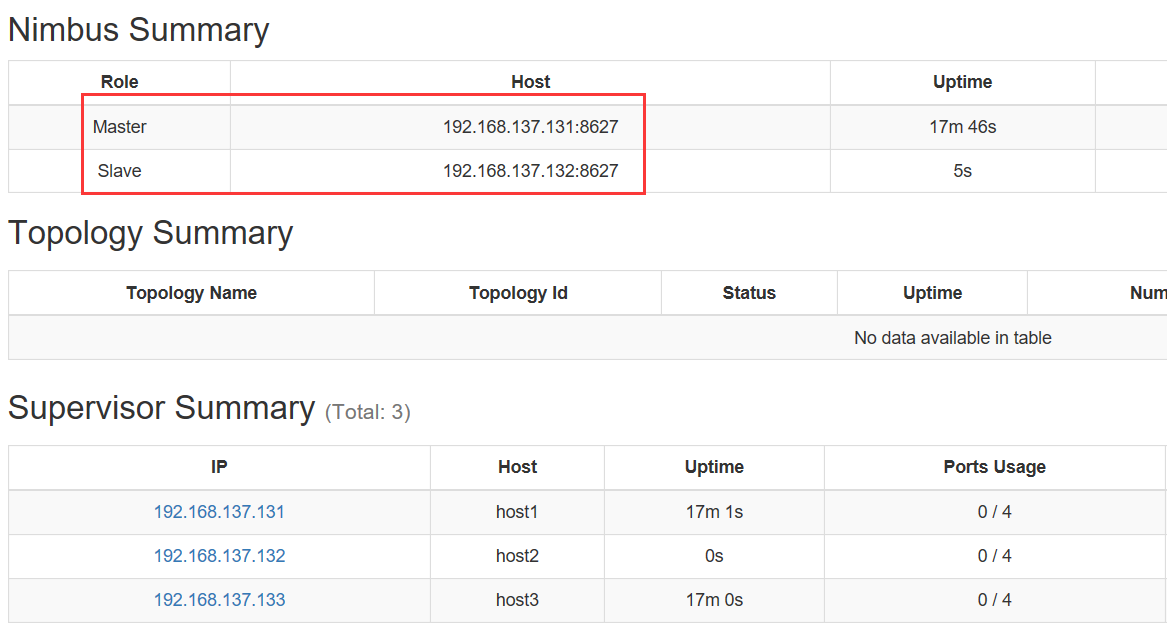
1.Nimbus实现HA:当一台nimbus挂了,自动热切到备份nimbus
示例:
nimbus在两个主机上都有:
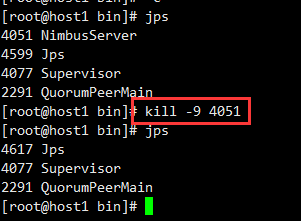
停止131主机上nimbus进程:
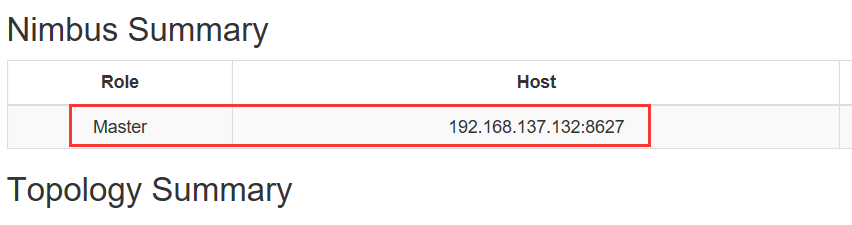
原nimbus的slave主机自动变为master:
2.原生Storm RPC:Zeromq使用堆外内存,导致OS内存不够,Netty导致OOM;JStorm底层RPC采用netty + disruptor,保证发送速度和接收速度是匹配的,彻底解决雪崩问题。
3.现有Strom,在添加supervisor或者supervisor shutdown时,会触发任务rebalance;提交新任务时,当worker数不够时,触发其他任务做rebalance。——在JStorm中不会发生,使得数据流更稳定。
4.新上线的任务不会冲击老的任务:新调度从cpu,memory,disk,net 四个角度对任务进行分配;已经分配好的新任务,无需去抢占老任务的cpu,memory,disk和net ——任务之间影响小。
5.Supervisor主线 ——more catch
6.Spout/Bolt 的open/prepare ——more catch
7.所有IO, 序列化,反序列化 ——more catch
8.减少对ZK的访问量:去掉大量无用的watch;task的心跳时间延长一倍;Task心跳检测无需全ZK扫描。
JStorm相比Storm调度更强大
1.彻底解决了storm 任务分配不均衡问题
2.从4个维度进行任务分配:CPU、Memory、Disk、Net
3.默认一个task,一个cpu slot。当task消耗更多的cpu时,可以申请更多cpu slot 解决新上线的任务去抢占老任务的cpu 一淘有些task内部起很多线程,单task消耗太多cpu
4.默认一个task,一个memory slot。当task需要更多内存时,可以申请更多内存slot 先海狗项目中,slot task 需要8G内存,而且其他任务2G内存就够了
5.默认task,不申请disk slot。当task 磁盘IO较重时,可以申请disk slot 海狗/实时同步项目中,task有较重的本地磁盘读写操作
6.可以强制某个component的task 运行在不同的节点上 聚石塔,海狗项目,某些task提供web Service服务,为了端口不冲突,因此必须强制这些task运行在不同节点上
7.可以强制topology运行在单独一个节点上 节省网络带宽 Tlog中大量小topology,为了减少网络开销,强制任务分配到一个节点上
8.可以自定义任务分配:提前预约任务分配到哪台机器上,哪个端口,多少个cpu slot,多少内存,是否申请磁盘 海狗项目中,部分task期望分配到某些节点上
9.可以预约上一次成功运行时的任务分配:上次task分配了什么资源,这次还是使用这些资源 CDO很多任务期待重启后,仍使用老的节点,端口
10.Spout nextTuple和ack/fail运行在不同线程
高级功能
JStorm 任务的动态伸缩
动态调整包括Task和Worker两个维度,
- Task维度: Spout, Bolt,Acker并发数的动态调整
- Worker维度: Worker数的动态调整
JStorm rebalance
USAGE: jstorm rebalance [-r] TopologyName [DelayTime] [NewConfig] e.g. jstorm rebalance TestTopology conf.yaml
参数说明: -r: 对所有task做重新调度 TopologyName: Topology任务的名字 DelayTime: 开始执行动态调整的延迟时间 NewConfig: Spout, Bolt, Acker, Worker的新配置(当前仅支持yaml格式的配置文件)
配置文件例子
topology.workers : 1 topology.acker.executors : 1
topology.spout.parallelism: TestSpout : 2 topology.bolt.parallelism: TestBolt : 4
【平衡之前】:
topologyBuilder.setBolt(bolt, new TestBolt(),2).localOrShuffleGrouping(spout);
config.setNumWorkers(1);
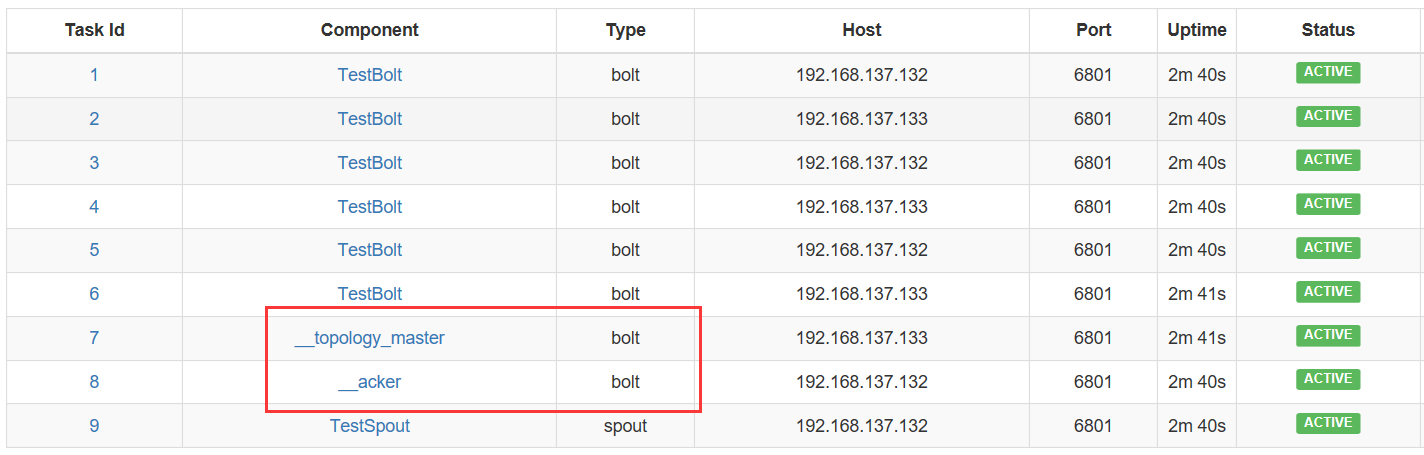
启动一个worker,两个TestBolt task
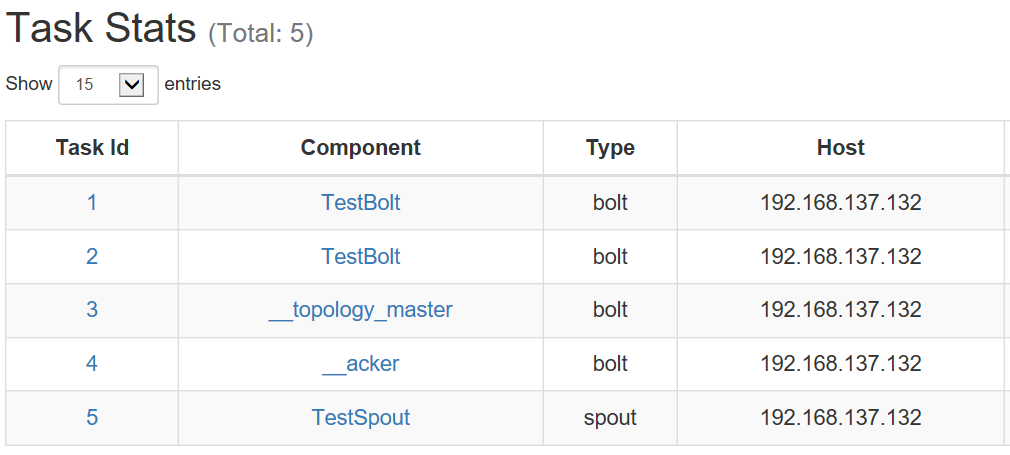
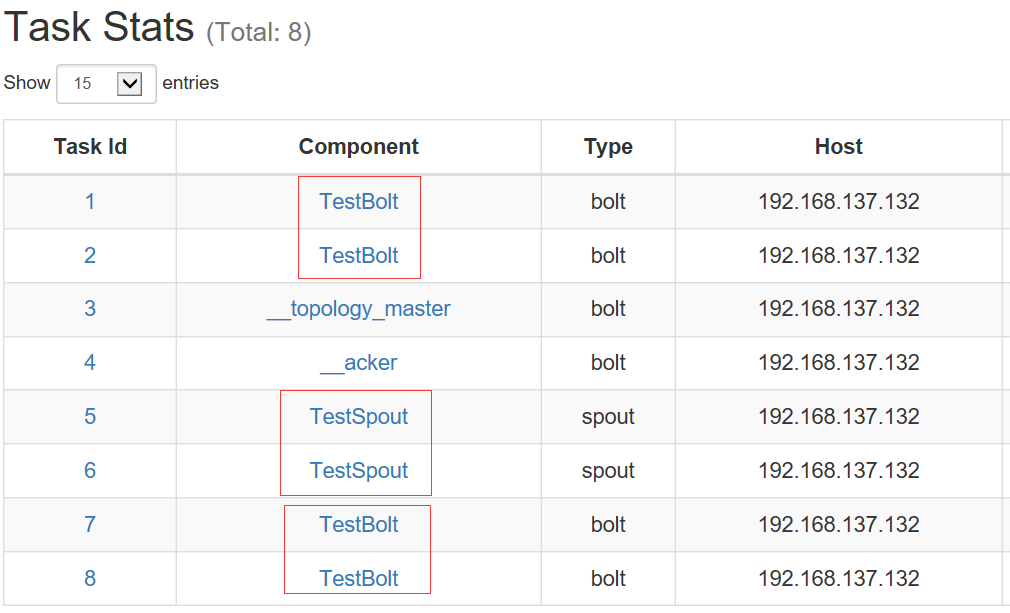
【平衡之后】(Bolt task个数由2个变更为4个,Spout task有1个变为2个):

Jstorm 支持动态更新配置文件
用户事先实现好的接口update()决定的。当用户提交动态更新配置文件的命令后,该函数会被回调。更新配置文件是以component为级别的,每个component都有自己的update,如果哪个component不需要实现配置文件动态更新,那它就无需继续该接口。
命令行方式
USAGE: jstorm update_topology TopologyName -conf configPath e.g. jstorm update_topology TestTopology –conf conf.yaml 参数说明: TopologyName: Topology任务的名字 configPath: 配置文件名称(暂时只支持yaml格式)
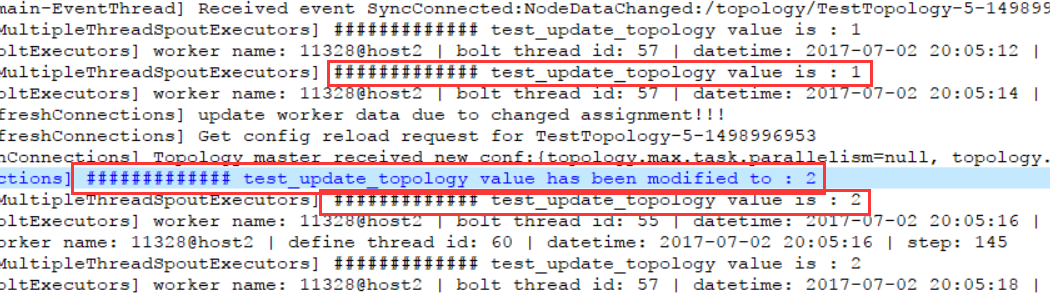
示例:
spout需要继承IDynamicComponent接口
public void nextTuple() {
collector.emit(new Values("abc"), UUID.randomUUID().toString());
logger.info("############# test_update_topology value is : {}", this.conf.get("test_update_topology"));
JStormUtils.sleepMs(2000);
}
......
@Override
public void update(Map conf) {
this.conf.put("test_update_topology", "2");
logger.info("############# test_update_topology value has been modified to : {}", this.conf.get("test_update_topology"));
}
执行更新命令:./jstorm update_topology TestTopology -conf ../jar/storm.yaml,通过日志可以看出更新前后的变化